RDBSのパフォーマンスは、SQL構文、Index、データサイズ等に依存していますが、SQL構文の得手不得手はデータベースの種類にもよって、オプティマイザーの処理が異なるので変わってきます。それぞれのRDBMSが苦手な処理を避けて書き換える事で対応する事が出来るでしょう。データサイズが経年と共に大きくなってきたら、パーティションを検討したり、古いデータを削除したりして対応する事も検討が必要になってくるかと思います。Indexに関しては、データベースを設計する段階で予め考慮してIndexを付けておくと同時に、運用の中で重い処理が出てきたらwhere句の処理で選択されている列を指定してインデックスを付けてあげると良いでしょう。その場合も複合インデックス等の場合は、SQLの処理によってはインデックスが使われない事があるので順番も気にすると良い場合もあるでしょう。インデックスは参照処理を高速化すると同時に、Insert、Update、Delete等の書き込み処理の場合にはインデックス更新を伴うのでシステム的にオーバーヘッドになります。不要なインデックスが存在している場合は適宜、削除してオーバヘッドを減らすと同時に、不要なディスク容量が増加しないように留意しておくと良いでしょう。
PostgreSQLの場合はpg_stat_user_indexes を利用
In case of PostgreSQL
rails_app=# \c development
You are now connected to database "development" as user "postgres".
taskleaf_development=# SELECT indexrelname, idx_scan, idx_tup_read, idx_tup_fetch FROM pg_stat_user_indexes;
indexrelname | idx_scan | idx_tup_read | idx_tup_fetch
---------------------------------------------+----------+--------------+---------------
schema_migrations_pkey | 30 | 195 | 195
ar_internal_metadata_pkey | 3 | 2 | 2
notes_pkey | 1455 | 1769 | 1751
users_pkey | 2202 | 2202 | 2202
index_users_on_email | 108 | 94 | 94
index_tasks_on_user_id | 306 | 1455 | 1453
active_storage_blobs_pkey | 112 | 112 | 112
index_active_storage_blobs_on_key | 0 | 0 | 0
active_storage_attachments_pkey | 0 | 0 | 0
index_active_storage_attachments_on_blob_id | 0 | 0 | 0
index_active_storage_attachments_uniqueness | 367 | 46 | 46
kbis_pkey | 0 | 0 | 0
(12 rows)
taskleaf_development=# ※ 起動してからの統計です。

- Script for finding unused-index on PG.
https://github.com/rdbms-at-twitter/PostgreSQL/blob/master/find_unused_index.sql
此方のSQLでは使われて無いIndexと設定されているテーブルも確認する事が可能です。
SELECT s.relname AS table_name,
indexrelname AS index_name,
CASE WHEN i.indisunique THEN 'Y'
ELSE 'N'
END AS unique,
idx_scan AS index_scans,
idx_scan AS idx_tup_read,
idx_scan AS idx_tup_fetch,
pg_size_pretty(pg_relation_size(quote_ident(s.indexrelname)::text)) AS index_size
FROM pg_catalog.pg_stat_user_indexes s,
pg_index i
WHERE i.indexrelid = s.indexrelid
and s.idx_scan = 0
and s.idx_tup_read = 0
and s.idx_tup_fetch = 0
and i.indisunique <> 'y';重複したIndexを確認するSQLの場合は以下の様になります。
SELECT indrelid::regclass table_name,
att.attname column_name,
amname index_method
FROM pg_index i,
pg_class c,
pg_opclass o,
pg_am a,
pg_attribute att
WHERE o.oid = ALL (indclass)
AND att.attnum = ANY(i.indkey)
AND a.oid = o.opcmethod
AND att.attrelid = c.oid
AND c.oid = i.indrelid
GROUP BY table_name,
att.attname,
indclass,
amname, indkey
HAVING count(*) > 1;MySQLの場合はSYS Schemaを利用
In case of MySQL
起動してから利用されてないIndexを特定(schema_unused_indexes)
root@localhost [sys]> select * from sys.schema_unused_indexes limit 5;
+---------------+--------------------+-----------------------------+
| object_schema | object_name | index_name |
+---------------+--------------------+-----------------------------+
| APP | FTS_Tweets | idx_mecab_text |
| APP | FTS_Tweets2 | idx_mecab_text |
| APP | FTS_Tweets20200518 | idx_mecab_text |
| APP | FTS_Tweets3 | idx_mecab_text |
| APP | password_resets | password_resets_email_index |
+---------------+--------------------+-----------------------------+
5 rows in set (0.01 sec)
root@localhost [sys]> select * from sys.schema_index_statistics limit 1\G
*************************** 1. row ***************************
table_schema: APP
table_name: sessions
index_name: sessions_id_unique
rows_selected: 14111
select_latency: 654.74 ms
rows_inserted: 0
insert_latency: 0 ps
rows_updated: 705
update_latency: 252.13 ms
rows_deleted: 6341
delete_latency: 127.89 ms
1 row in set (0.00 sec)
root@localhost [sys]> ※起動してからの統計になるので、暫く運用してから利用していないインデックスを確認して下さい。
≒ 起動時は殆どがUn-Used Indexになっています。
重複したインデックスの特定と削除 ( schema_redundant_indexes )
このViewを利用すると、重複したインデックスと対象インデックスを削除するためのDDLを表示してくれます。
root@localhost [sys]> select * from sys.schema_redundant_indexes\G
*************************** 1. row ***************************
table_schema: confirm
table_name: memo
redundant_index_name: idx_text2
redundant_index_columns: data
redundant_index_non_unique: 1
dominant_index_name: idx_text1
dominant_index_columns: data
dominant_index_non_unique: 1
subpart_exists: 1
sql_drop_index: ALTER TABLE `confirm`.`memo` DROP INDEX `idx_text2`
1 row in set (0.01 sec)
root@localhost [sys]> 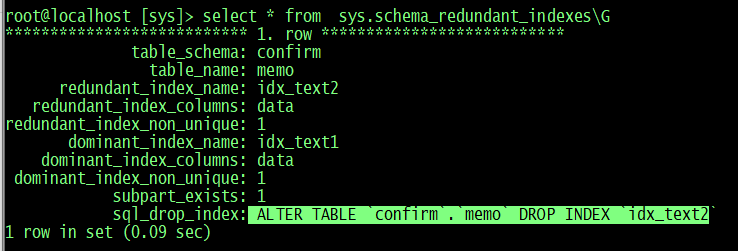
MySQLとPostgreSQLの実行プランの基本的な確認方法
その他、インデックスに関しての理解
データベースによって利用可能なインデックスに差異はありますが、基本的に考え方としては大きな差異は無いので、インデックス作成時に以下のページも参考になるかと思います。