
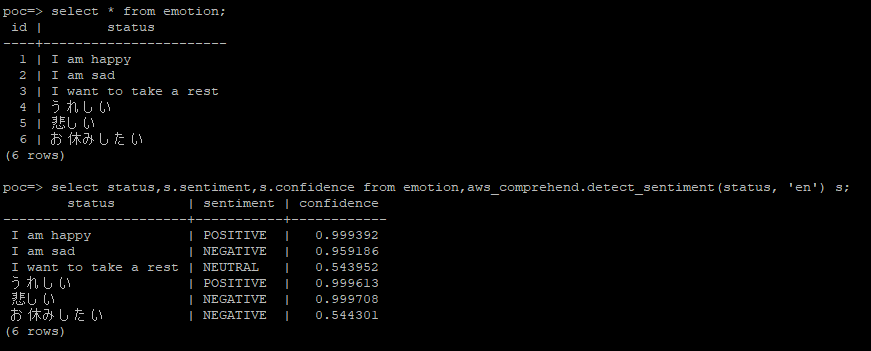
Amazon Bedrock は、基礎モデル (FM) を使用して生成 AI アプリケーションを構築および拡張する最も簡単な方法です。 FM は膨大な量のデータに基づいてトレーニングされており、それらのデータを使用してさ […]
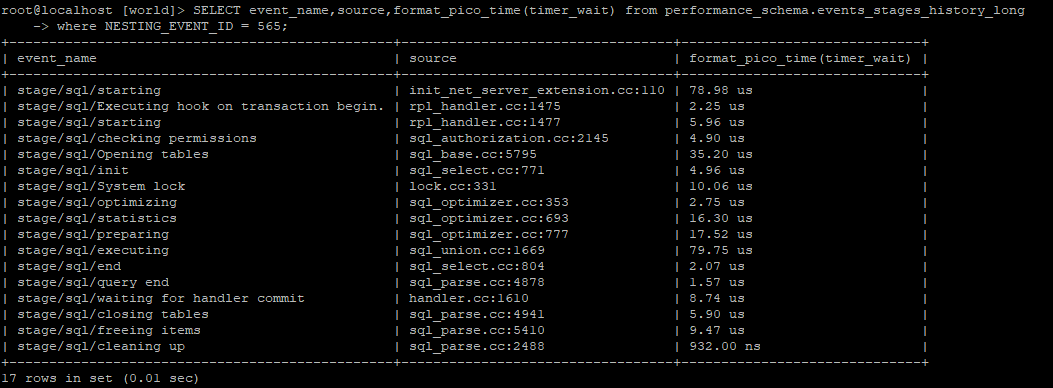
SQLの処理に時間がかかっている場合は、基本的にEXPLAINで実行プランを確認して頂き、必要に応じてパフォーマンスチューニングして頂きますが、更にSQLのどのイベントで時間がかかっているか確認したい時はprofilin […]
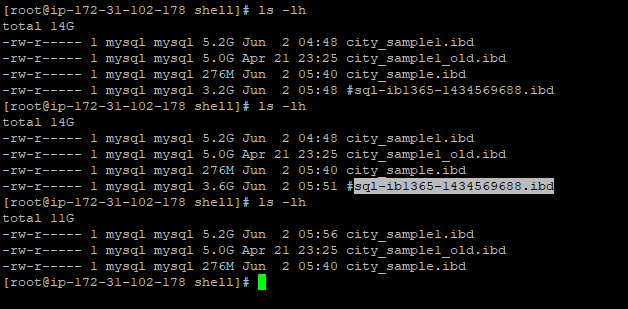
OPTIMIZE TABLEを実行する代わりに、以下の様にALTER TABLEを実行するケースも多いと思います。バックグラウンドでどの様に処理しているかを聞かれる事も多いのでこちらにメモしておきます。 OPTIMIZE […]
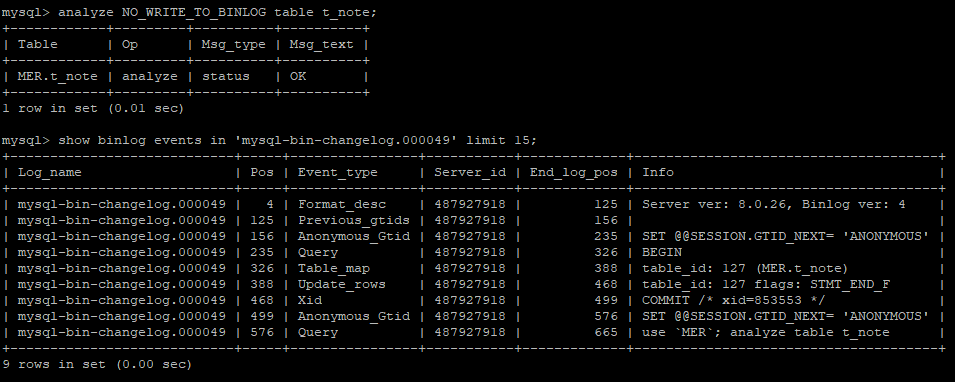
Analyze Tableがレプリケートされない様にNO_WRITE_TO_BINLOGオプションを付けた場合のバイナリーログの確認。殆どのケースで参照側でAnalyzeが実行されても問題は無いと思うが、サンプリングのオ […]
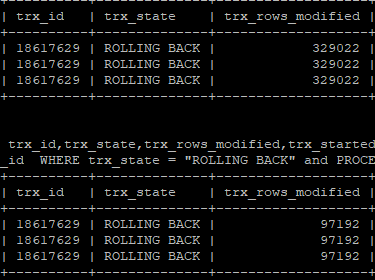
もしMySQLにおいてROLLBACK処理が発生したら?どのくらい時間がかかるか確認する為の指標。 START TRANSACTIONまたはBEGINでを使用すると、トランザクションを COMMIT または ROLLBA […]
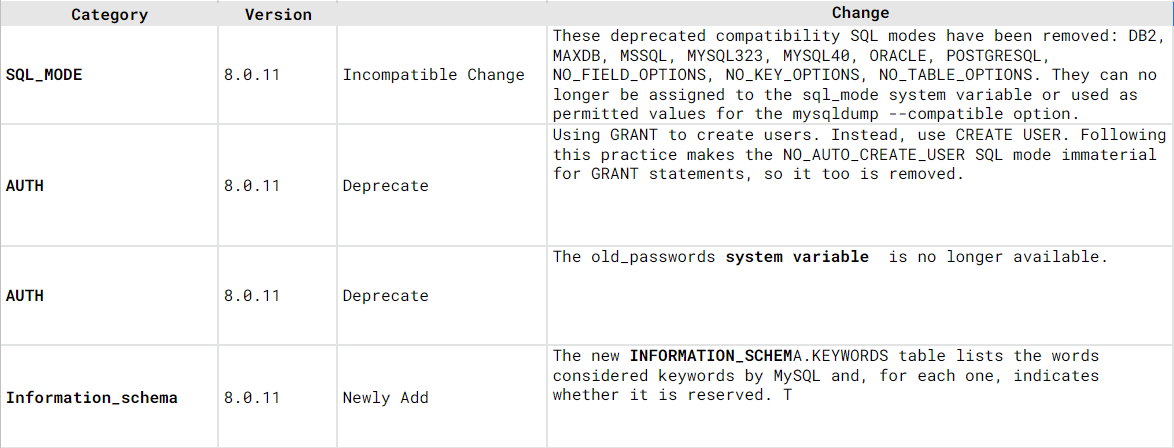
MySQL8.0.11からMySQL8.0.31で気になった部分だけ新機能と変更点をまとめました。(約150位)ただ、変更点が多く、全てを網羅出来てません。確認が必要な場合は適宜リリースノートやマニュアルを確認して下さい […]
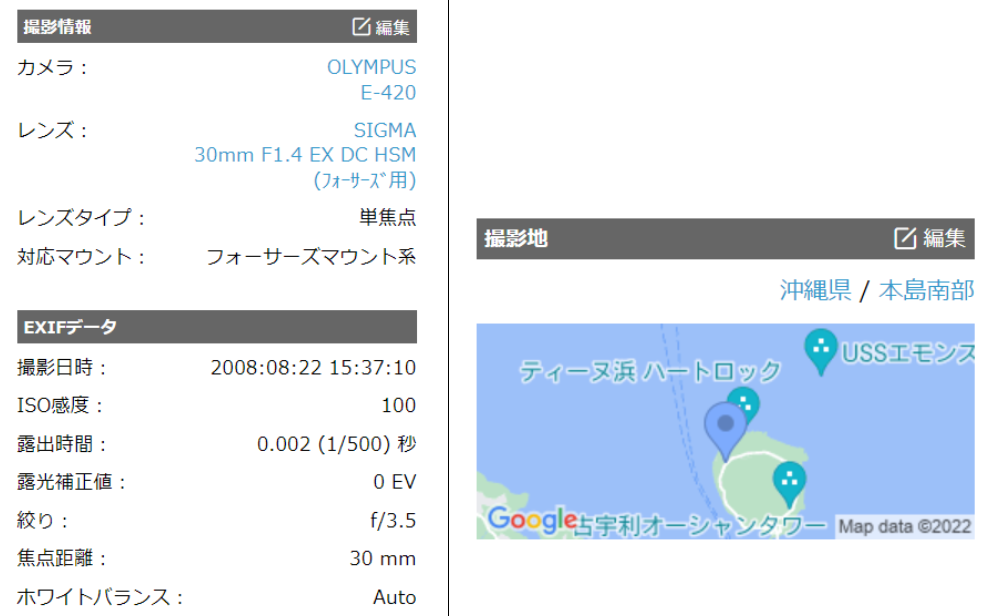
こちらは、RDBMS-GIS(MySQL,PostgreSQLなど) Advent Calendar 2022 の23日目の記事になります。 過去2回は、”日本の観光資源データを可視化してみた […]
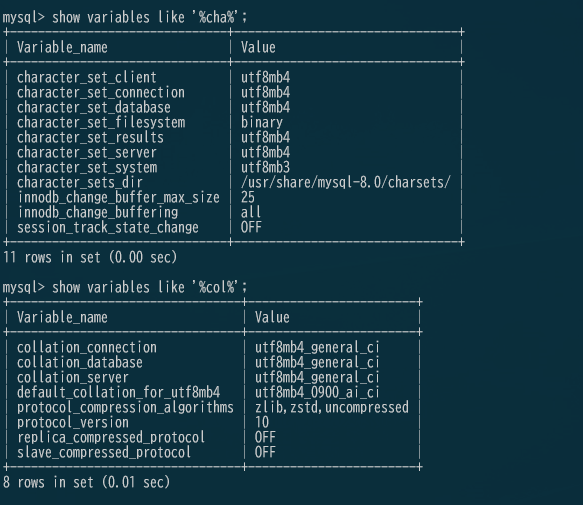
以前に文字コードに関して少しまとめましたが、サーバー初期設定時のMySQL8.0のperformance_schemaはutf8mb4_0900_ai_ciになっていて、default_collation_for_utf […]
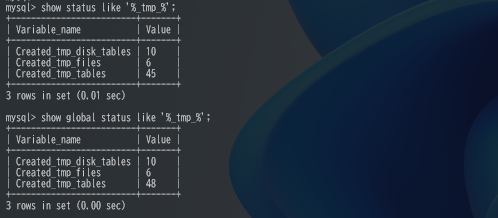
MySQL8.0.16のリリースノートに以下の様にTempTableの処理に変更が加わっていたので仕様を把握する為に、追加されたパラメータと挙動に関して確認してみました。見ていると、8.0.23での変更や、8.0.26に […]
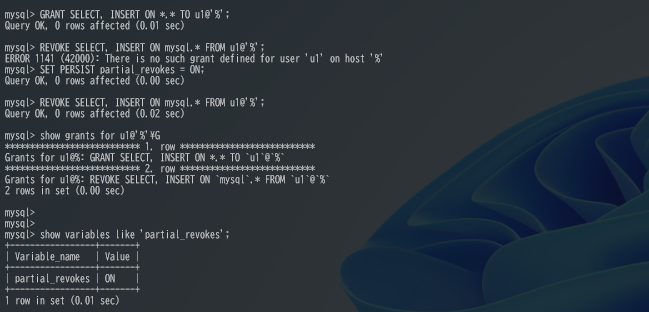
MySQL8.0.16のリリースノートにアカウントに広い範囲で権限を付与した後に、特定の権限だけREVOKEする方法についての機能追加が実装されていたので確認してみました。 Previously, it was not […]