類似した文字があった場合にHEX化する事で違いを分かりやすく表現する方法。
MySQLの場合は、HEXにする事で文字列または数値を 16 進形式の文字列に変換する事が出来るので、HEX()関数で確認する事が可能です。
In case of MySQL
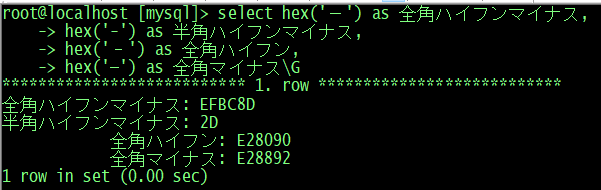
root@localhost [mysql]> select hex('-') as 全角ハイフンマイナス,hex('-') as 半角ハイフンマイナス,hex('‐') as 全角ハイフン ,hex('−') as 全角マイナス\G
*************************** 1. row ***************************
全角ハイフンマイナス: EFBC8D
半角ハイフンマイナス: 2D
全角ハイフン: E28090
全角マイナス: E28892
1 row in set (0.00 sec)
PostgreSQLの場合は、encode(‘文字列’, ‘hex’)で 文字列または数値を 16 進形式の文字列に変換する事が出来ます。
In Case of PostgreSQL
postgres=# \x
Expanded display is on.
postgres=# select encode('-', 'hex') as 全角ハイフンマイナス,encode('-', 'hex') as 半角ハイフンマイナス,encode('‐', 'hex') as 全角ハイフン ,encode('−', 'hex') as 全角マイナス;
-[ RECORD 1 ]--------+-------
全角ハイフンマイナス | efbc8d
半角ハイフンマイナス | 2d
全角ハイフン | e28090
全角マイナス | e28892
postgres=# 
postgres=# select station_name,encode(station_name::bytea,'hex') from stations where station_name like '宮崎%';
station_name | encode
--------------+--------------------
宮崎駅 | e5aeaee5b48ee9a785