
全文検索を用いると、複数の文書から特定の文字列、単語を検索する事が出来る。通常のB-Treeインデックス等だと文字列に対して、LIKE検索すると結果として全てのテーブルのデータを参照しパフォーマンス的に耐える事が出来ないケースが多いが、全文検索は単語が存在する文書に対してインデックスを貼って単語を含むドキュメントを高速に検索する事が出来る。Elastic Search等の専用のソフトもあるが、RDBMSに組み込まれている全文検索を利用すると、低コストでサクットカジュアルに実装する事が可能です。勿論、データ量や用途にもよるので適宜使い分けして下さい。
In Case of MySQL
MySQLでは、ngramやmecabを利用した全文検索が利用可能です。
全文検索を利用している場合は、LIKE検索(前方一致以外)と異なりINDEXを利用して検索出来ています。
ngram
root@localhost [FTS]> show create table T_Ngram\G
*************************** 1. row ***************************
Table: T_Ngram
Create Table: CREATE TABLE `T_Ngram` (
`FTS_DOC_ID` bigint unsigned NOT NULL AUTO_INCREMENT,
`title` varchar(100) DEFAULT NULL,
`description` varchar(1000) DEFAULT NULL,
PRIMARY KEY (`FTS_DOC_ID`),
FULLTEXT KEY `ngram_idx` (`description`) /*!50100 WITH PARSER `ngram` */
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
1 row in set (0.01 sec)
root@localhost [FTS]>
root@localhost [FTS]> insert into T_Ngram(title,description)
-> values('binlog-format','行ベース、ステートメントベース、または複合型のレプリケーションのいずれを使用するか指定します。'),
-> ('default-storage-engine','テーブルのデフォルトストレージエンジンを設定します。'),
-> ('log-queries-not-using-indexes','すべての行を取得することが予想されるクエリーがログに記録されます。');
Query OK, 3 rows affected (0.00 sec)
Records: 3 Duplicates: 0 Warnings: 0
root@localhost [FTS]>
root@localhost [FTS]> select * from T_Ngram\G
*************************** 1. row ***************************
FTS_DOC_ID: 1
title: binlog-format
description: 行ベース、ステートメントベース、または複合型のレプリケーションのいずれを使用するか指定します。
*************************** 2. row ***************************
FTS_DOC_ID: 2
title: default-storage-engine
description: テーブルのデフォルトストレージエンジンを設定します。
*************************** 3. row ***************************
FTS_DOC_ID: 3
title: log-queries-not-using-indexes
description: すべての行を取得することが予想されるクエリーがログに記録されます。
3 rows in set (0.00 sec)
root@localhost [FTS]>
root@localhost [FTS]> SELECT * FROM T_Ngram WHERE MATCH(description) AGAINST('記録' IN BOOLEAN MODE)\G
*************************** 1. row ***************************
FTS_DOC_ID: 3
title: log-queries-not-using-indexes
description: すべての行を取得することが予想されるクエリーがログに記録されます。
1 row in set (0.00 sec)
root@localhost [FTS]> EXPLAIN SELECT * FROM T_Ngram WHERE MATCH(description) AGAINST('記録' IN BOOLEAN MODE)\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: T_Ngram
partitions: NULL
type: fulltext
possible_keys: ngram_idx
key: ngram_idx
key_len: 0
ref: const
rows: 1
filtered: 100.00
Extra: Using where; Ft_hints: no_ranking
1 row in set, 1 warning (0.00 sec)
root@localhost [FTS]>
root@localhost [FTS]> SELECT * FROM T_Ngram WHERE MATCH(description) AGAINST ('記録' IN NATURAL LANGUAGE MODE)\G
*************************** 1. row ***************************
FTS_DOC_ID: 3
title: log-queries-not-using-indexes
description: すべての行を取得することが予想されるクエリーがログに記録されます。
1 row in set (0.00 sec)
root@localhost [FTS]> EXPLAIN SELECT * FROM T_Ngram WHERE MATCH(description) AGAINST ('記録' IN NATURAL LANGUAGE MODE)\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: T_Ngram
partitions: NULL
type: fulltext
possible_keys: ngram_idx
key: ngram_idx
key_len: 0
ref: const
rows: 1
filtered: 100.00
Extra: Using where; Ft_hints: sorted
1 row in set, 1 warning (0.00 sec)
root@localhost [FTS]>
root@localhost [FTS]> select * from T_Ngram WHERE description like '%記録%'\G
*************************** 1. row ***************************
FTS_DOC_ID: 3
title: log-queries-not-using-indexes
description: すべての行を取得することが予想されるクエリーがログに記録されます。
1 row in set (0.00 sec)
root@localhost [FTS]> EXPLAIN select * from T_Ngram WHERE description like '%記録%'\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: T_Ngram
partitions: NULL
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 3
filtered: 33.33
Extra: Using where
1 row in set, 1 warning (0.00 sec)
root@localhost [FTS]> 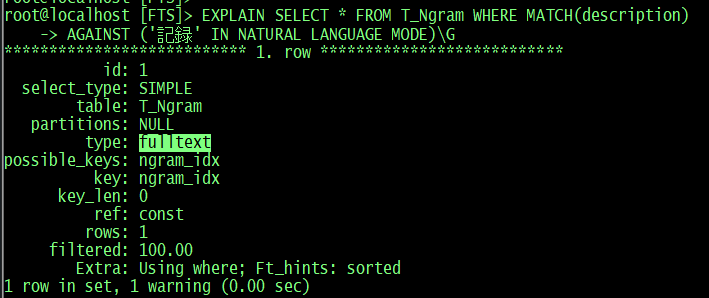
Mecab
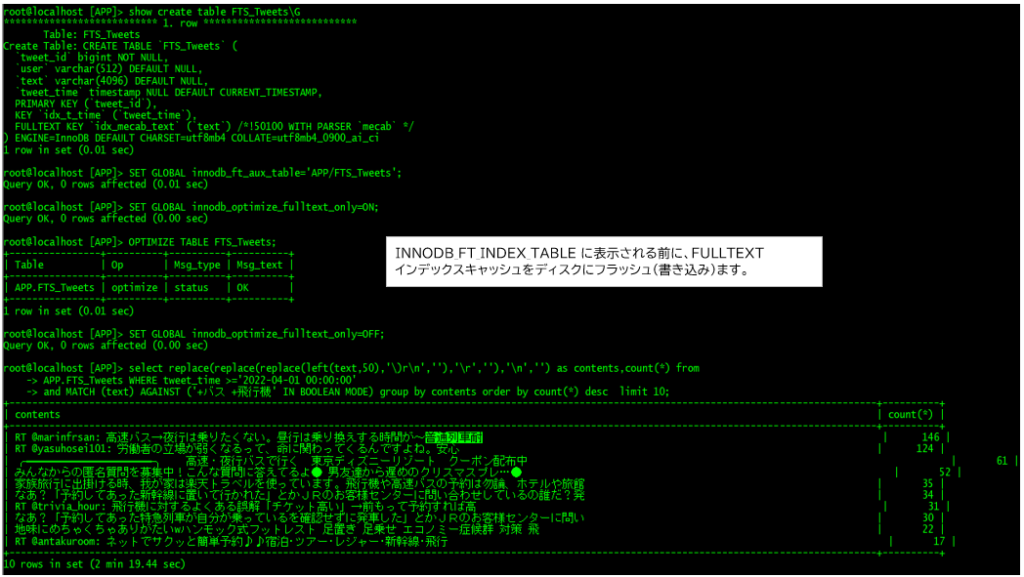
root@localhost [mysql]> SET GLOBAL innodb_ft_aux_table='APP/FTS_Tweets';
Query OK, 0 rows affected (0.00 sec)
root@localhost [mysql]> SET GLOBAL innodb_optimize_fulltext_only=ON;optimize table APP.FTS_Tweets;
Query OK, 0 rows affected (0.00 sec)
+----------------+----------+----------+----------+
| Table | Op | Msg_type | Msg_text |
+----------------+----------+----------+----------+
| APP.FTS_Tweets | optimize | status | OK |
+----------------+----------+----------+----------+
1 row in set (0.05 sec)
root@localhost [mysql]> exit
Bye
[root@data]# mysql -u root -p -e "select replace(replace(replace(left(text,80),'\)r\n',''),'\r',''),'\n','') as text,DATE_FORMAT(tweet_time,'%Y%c%d') tweet_date,count(*) from APP.FTS_Tweets
WHERE MATCH (text) AGAINST ('+コロナ' IN BOOLEAN MODE) and tweet_time >= '2020-10-01 00:00:00' and tweet_time < '2020-11-01 00:00:00' group by text,tweet_date order by count(*) desc limit 3\G";
Enter password:
*************************** 1. row ***************************
text: RT @mainichi: 東京都が1日、臨海部と都心を結ぶバス高速輸送システム「東京BRT」の運行を開始しました。5月に運行を始める予定でしたが、新型コロナウ
tweet_date: 20201001
count(*): 26
*************************** 2. row ***************************
text: RT @Session_1530: 【#追っかけ再生】10/13(火)特集「コロナ危機に直面するバス業界の現状と課題」出演:成定竜一さん(高速バスマーケティ
tweet_date: 20201013
count(*): 22
*************************** 3. row ***************************
text: RT @tokyu_bus: 【高速乗合】東急沿線から高速バスで草津温泉・軽井沢へ!!2020年12月よりたまプラーザ・二子玉川・渋谷から草津温泉まで毎日4往復
tweet_date: 20201012
count(*): 20
[root@data]# mysql -u root -p -e "select replace(replace(replace(left(text,80),'\)r\n',''),'\r',''),'\n','') as text,DATE_FORMAT(tweet_time,'%Y%c%d') tweet_date,count(*) from APP.FTS_Tweets
WHERE MATCH (text) AGAINST ('+コロナ' IN BOOLEAN MODE) and tweet_time >= '2021-10-01 00:00:00' and tweet_time < '2021-11-01 00:00:00' group by text,tweet_date order by count(*) desc limit 3\G";
Enter password:
*************************** 1. row ***************************
text: RT @ngs_keneibus: 新型コロナウイルスの影響で運休していた県外向け高速バスにつきまして、今日から3路線の運行を再開します。引き続き感染防止対策
tweet_date: 20211009
count(*): 80
*************************** 2. row ***************************
text: RT @green_purplebus: 新型コロナウイルスの影響により全便運休中の高速バス「#あそう号(鉾田・麻生・潮来・佐原~東京線)」は、運行本数・時刻を
tweet_date: 20211003
count(*): 19
*************************** 3. row ***************************
text: RT @ngs_keneibus: 新型コロナウイルスの影響で運休していた県外向け高速バスにつきまして、今日から3路線の運行を再開します。引き続き感染防止対策
tweet_date: 20211008
count(*): 16
[root@data]# Scoreの確認
root@localhost [mecab]> select PLUGIN_NAME,PLUGIN_VERSION,PLUGIN_LICENSE from information_schema.plugins where PLUGIN_NAME IN ('ngram','mecab');
+-------------+----------------+----------------+
| PLUGIN_NAME | PLUGIN_VERSION | PLUGIN_LICENSE |
+-------------+----------------+----------------+
| ngram | 0.1 | GPL |
| mecab | 0.1 | GPL |
+-------------+----------------+----------------+
2 rows in set (0.00 sec)
root@localhost [mecab]>
root@localhost [mecab]> CREATE TABLE M_DEMO_MB4
-> (
-> FTS_M_ID BIGINT UNSIGNED AUTO_INCREMENT NOT NULL PRIMARY KEY,
-> title VARCHAR(100),
-> FULLTEXT INDEX mecab_idx(title) WITH PARSER mecab
-> ) Engine=InnoDB CHARACTER SET utf8mb4;
Query OK, 0 rows affected (0.03 sec)
root@localhost [mecab]>
root@localhost [mecab]> INSERT INTO M_DEMO_MB4 (title) VALUES ('東京都は日本の首都です'),('京都と大阪は日本の府です');
Query OK, 2 rows affected (0.00 sec)
Records: 2 Duplicates: 0 Warnings: 0
root@localhost [mecab]> INSERT INTO M_DEMO_MB4 (title) VALUES ('mysql');
Query OK, 1 row affected (0.01 sec)
root@localhost [mecab]> INSERT INTO M_DEMO_MB4 (title) VALUES ('MYSQL');
Query OK, 1 row affected (0.00 sec)
root@localhost [mecab]> INSERT INTO M_DEMO_MB4 (title) VALUES ('MySQL');
Query OK, 1 row affected (0.00 sec)
root@localhost [mecab]> INSERT INTO M_DEMO_MB4 (title) VALUES ('マイエスキューエル');
Query OK, 1 row affected (0.00 sec)
root@localhost [mecab]> INSERT INTO M_DEMO_MB4 (title) VALUES ('マイエスキューエル');
Query OK, 1 row affected (0.00 sec)
root@localhost [mecab]> INSERT INTO M_DEMO_MB4 (title) VALUES ('まいえすきゅーえる');
Query OK, 1 row affected (0.00 sec)
root@localhost [mecab]>
root@localhost [mecab]> SELECT * FROM INFORMATION_SCHEMA.INNODB_FT_INDEX_CACHE ORDER BY doc_id, position;
Empty set (0.01 sec)
root@localhost [mecab]> SET GLOBAL innodb_ft_aux_table="mecab/M_DEMO_MB4";
Query OK, 0 rows affected (0.00 sec)
root@localhost [mecab]> SELECT * FROM INFORMATION_SCHEMA.INNODB_FT_INDEX_CACHE ORDER BY doc_id, position;
+-----------------------------+--------------+-------------+-----------+--------+----------+
| WORD | FIRST_DOC_ID | LAST_DOC_ID | DOC_COUNT | DOC_ID | POSITION |
+-----------------------------+--------------+-------------+-----------+--------+----------+
| 東京 | 2 | 2 | 1 | 2 | 0 |
| 日本 | 2 | 3 | 2 | 2 | 12 |
| 首都 | 2 | 2 | 1 | 2 | 21 |
| です | 2 | 3 | 2 | 2 | 27 |
| 京都 | 3 | 3 | 1 | 3 | 0 |
| 大阪 | 3 | 3 | 1 | 3 | 9 |
| 日本 | 2 | 3 | 2 | 3 | 18 |
| です | 2 | 3 | 2 | 3 | 30 |
| mysql | 4 | 6 | 3 | 4 | 0 |
| mysql | 4 | 6 | 3 | 5 | 0 |
| mysql | 4 | 6 | 3 | 6 | 0 |
| マイエスキューエル | 7 | 7 | 1 | 7 | 0 |
| マイエスキューエル | 8 | 8 | 1 | 8 | 0 |
| いえ | 9 | 9 | 1 | 9 | 3 |
| すき | 9 | 9 | 1 | 9 | 9 |
| える | 9 | 9 | 1 | 9 | 21 |
+-----------------------------+--------------+-------------+-----------+--------+----------+
16 rows in set (0.00 sec)
root@localhost [mecab]> SELECT FTS_M_ID,title,MATCH (title) AGAINST('日本の首都' IN NATURAL LANGUAGE MODE) AS score FROM M_DEMO_MB4;
+----------+--------------------------------------+--------------------+
| FTS_M_ID | title | score |
+----------+--------------------------------------+--------------------+
| 1 | 東京都は日本の首都です | 1.178047776222229 |
| 2 | 京都と大阪は日本の府です | 0.3624762296676636 |
| 3 | mysql | 0 |
| 4 | MYSQL | 0 |
| 5 | MySQL | 0 |
| 6 | マイエスキューエル | 0 |
| 7 | マイエスキューエル | 0 |
| 8 | まいえすきゅーえる | 0 |
+----------+--------------------------------------+--------------------+
8 rows in set (0.00 sec)
root@localhost [mecab]> SELECT FTS_M_ID,title,MATCH (title) AGAINST('日本の首都' IN BOOLEAN MODE) AS score FROM M_DEMO_MB4;
+----------+--------------------------------------+-------------------+
| FTS_M_ID | title | score |
+----------+--------------------------------------+-------------------+
| 1 | 東京都は日本の首都です | 1.178047776222229 |
| 2 | 京都と大阪は日本の府です | 0 |
| 3 | mysql | 0 |
| 4 | MYSQL | 0 |
| 5 | MySQL | 0 |
| 6 | マイエスキューエル | 0 |
| 7 | マイエスキューエル | 0 |
| 8 | まいえすきゅーえる | 0 |
+----------+--------------------------------------+-------------------+
8 rows in set (0.00 sec)Scoreを確認してみる (出現頻度によるドキュメントの優先度)
select
tweet_id, MATCH (text) AGAINST ('+東京 +大阪 +ディスニー' IN BOOLEAN MODE) as score,
replace(replace(replace(left(text,20),'\)r\n',''),'\r',''),'\n','') as contents
from APP.FTS_Tweets WHERE tweet_time >='2022-04-01 00:00:00'
and MATCH (text) AGAINST ('+東京 +大阪 +ディスニー' IN BOOLEAN MODE) order by score desc limit 10;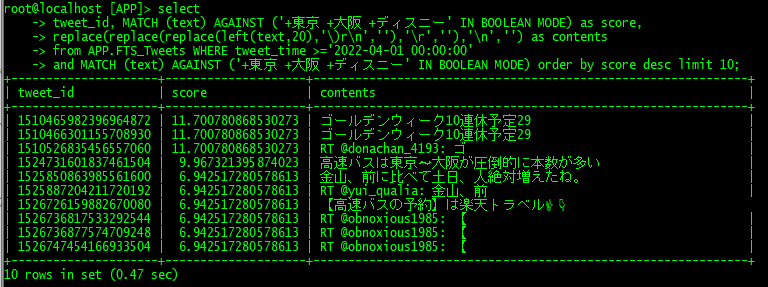
参照:Mecabのインストール方法
https://dev.mysql.com/doc/refman/8.0/ja/fulltext-search-mecab.html
※ngramはDefaultでインストールされていますが、Mecabを利用する場合は追加でプラグインをインストールする必要があります。
root@localhost [mysql]> select * from plugin;
+-------+-------------------+
| name | dl |
+-------+-------------------+
| mecab | libpluginmecab.so |
+-------+-------------------+
1 row in set (0.00 sec)
root@localhost [mysql]> exit
Bye
[root@data]# cat /etc/my.cnf | grep mecab
loose-mecab-rc-file=/usr/local/mysql/lib/mecab/etc/mecabrc
[root@data]# cat /usr/local/mysql/lib/mecab/etc/mecabrc | grep dicdir
; dicdir = /path/to/mysql/lib/mecab/lib/mecab/dic/ipadic_euc-jp
dicdir = /usr/local/mysql/lib/mecab/dic/ipadic_utf-8
[root@data]# | 例)バスと飛行機が含まれるTweet |
 |
In case of PostgreSQL
PostgreSQLでは、pg_trgmという全文検索モジュールが付属されていますが、pg_trgmはマルチバイト文字列の検索には適していない為、マルチバイト文字列を扱う全文検索用にpg_bigmを利用する事が可能です。
development-# CREATE EXTENSION pg_bigm;
CREATE EXTENSION
development=# \d tasks;
Table "public.tasks"
Column | Type | Modifiers
-------------+-----------------------------+----------------------------------------------------
id | bigint | not null default nextval('tasks_id_seq'::regclass)
name | character varying(100) | not null
description | text |
created_at | timestamp without time zone | not null
updated_at | timestamp without time zone | not null
user_id | bigint | not null
Indexes:
"tasks_pkey" PRIMARY KEY, btree (id)
"index_tasks_on_user_id" btree (user_id)
development=# explain select count(*) from tasks where description like '%ダンプ%';
QUERY PLAN
------------------------------------------------------------
Aggregate (cost=28.49..28.50 rows=1 width=0)
-> Seq Scan on tasks (cost=0.00..28.49 rows=1 width=0)
Filter: (description ~~ '%ダンプ%'::text)
(3 rows)
development=# create index idx_bigram_task_description on tasks using gin (description gin_bigm_ops);
CREATE INDEX
development=# \d tasks;
Table "public.tasks"
Column | Type | Modifiers
-------------+-----------------------------+----------------------------------------------------
id | bigint | not null default nextval('tasks_id_seq'::regclass)
name | character varying(100) | not null
description | text |
created_at | timestamp without time zone | not null
updated_at | timestamp without time zone | not null
user_id | bigint | not null
Indexes:
"tasks_pkey" PRIMARY KEY, btree (id)
"idx_bigram_task_description" gin (description gin_bigm_ops)
"index_tasks_on_user_id" btree (user_id)
development=# explain select count(*) from tasks where description like '%ダンプ%';
QUERY PLAN
-------------------------------------------------------------------------------------------------
Aggregate (cost=24.02..24.03 rows=1 width=0)
-> Bitmap Heap Scan on tasks (cost=20.00..24.01 rows=1 width=0)
Recheck Cond: (description ~~ '%ダンプ%'::text)
-> Bitmap Index Scan on idx_bigram_task_description (cost=0.00..20.00 rows=1 width=0)
Index Cond: (description ~~ '%ダンプ%'::text)
(5 rows)
development=# 参照: pg_bigmのインストールや仕様等