データサイズが増加し続け、シングルテーブルに格納するとサービスに影響が出てしまう場合で、且つ実行しているSQLがパーティションに設定したデータ分散用のキー(日付等)によってフィルター出来る場合にパーティションは非常に有用だと思います。ログ系のデータ蓄積等は溜めるだけで、且つ時系列になっているのでパーティションにて取り扱い易いデータの一つかと思います。
- データを特定のカラムの値によって分類して格納
- パーティション毎にデータを分散し格納
- パーティション毎のインデックス
- データ削除時に特定のパーティションを削除可能(Vacuumを回避等)
- パーティションを追加する事でデータ増加に柔軟に対応
- 範囲外のデータはDefaultパーティションに格納可能(Alterでパーティションに分割可能)
- RDBMSによって、グローバルインデックスのサポート可否の差異がある。
PostgreSQL Partition
PostgreSQLでは、RANGE、LIST、HASHパーティショニングをサポートしています。
| Range | カラム値の範囲を指定して、テーブルをパーティションに分割 |
| List | キーの値を明示的に列挙して、テーブルをパーティションに分割 |
| Hash | 数値カラムのハッシュ値で分けて、テーブルをパーティションに分割 |
- PostgreSQLによるパーティション設定例
CREATE SEQUENCE travel_data_id START 1;
CREATE TABLE sample_travel_data (
id bigint not null default nextval('travel_data_id'),
dept_date date not null,
dept_time time without time zone not null,
arrival_date date not null,
arrival_time time without time zone not null,
transit_flag int not null default 0,
travel_name varchar(100) not null default 'free plan',
curreated_at timestamp without time zone not null,
updated_at timestamp without time zone not null,
PRIMARY KEY (id,dept_date)
) PARTITION BY RANGE (dept_date);
CREATE TABLE travel_y2022m01 PARTITION OF sample_travel_data
FOR VALUES FROM ('2022-01-01') TO ('2022-01-31');
CREATE TABLE travel_y2022m02 PARTITION OF sample_travel_data
FOR VALUES FROM ('2022-02-01') TO ('2022-02-28');
CREATE TABLE travel_y2022m03 PARTITION OF sample_travel_data
FOR VALUES FROM ('2022-03-01') TO ('2022-03-31');
oversea=> insert into sample_travel_data(dept_date,dept_time,arrival_date,arrival_time,curreated_at,updated_at) values('2022-01-01','12:30','2022-01-02','10:30',current_timestamp,current_timestamp);
INSERT 0 1
oversea=> insert into sample_travel_data(dept_date,dept_time,arrival_date,arrival_time,curreated_at,updated_at) values('2022-01-11','12:30','2022-01-02','10:30',current_timestamp,current_timestamp);
INSERT 0 1
oversea=> insert into sample_travel_data(dept_date,dept_time,arrival_date,arrival_time,curreated_at,updated_at) values('2022-01-21','12:30','2022-01-02','10:30',current_timestamp,current_timestamp);
INSERT 0 1
oversea=> insert into sample_travel_data(dept_date,dept_time,arrival_date,arrival_time,curreated_at,updated_at) values('2022-02-21','12:30','2022-02-23','10:30',current_timestamp,current_timestamp);
INSERT 0 1
oversea=> insert into sample_travel_data(dept_date,dept_time,arrival_date,arrival_time,curreated_at,updated_at) values('2022-02-21','12:30','2022-02-22','10:30',current_timestamp,current_timestamp);
INSERT 0 1
oversea=> insert into sample_travel_data(dept_date,dept_time,arrival_date,arrival_time,curreated_at,updated_at) values('2022-02-10','12:30','2022-02-12','10:30',current_timestamp,current_timestamp);
INSERT 0 1
oversea=> insert into sample_travel_data(dept_date,dept_time,arrival_date,arrival_time,curreated_at,updated_at) values('2022-03-10','12:30','2022-03-12','10:30',current_timestamp,current_timestamp);
INSERT 0 1
oversea=>
oversea=> CREATE INDEX ON travel_y2022m01(dept_date);
CREATE INDEX
oversea=> CREATE INDEX ON travel_y2022m02(dept_date);
CREATE INDEX
oversea=> CREATE INDEX ON travel_y2022m03(dept_date);
CREATE INDEX
oversea=>
留意:ALTER TABLEする時は、パーティションの子テーブルに継承する必用があるので、ONLYは付けない様にしてください。
- パーティション環境でのEXPLAIN
POC=# explain analyze select * from sample_travel_data where dept_date = '2022-01-01';
QUERY PLAN
--------------------------------------------------------------------------------------------------------------
Seq Scan on travel_y2022m01 sample_travel_data (cost=0.00..1.04 rows=1 width=270) (actual time=0.006..0.007 rows=1 loops=1)
Filter: (dept_date = '2022-01-01'::date)
Rows Removed by Filter: 2
Planning Time: 1.240 ms
Execution Time: 0.055 ms
(5 rows)
POC=#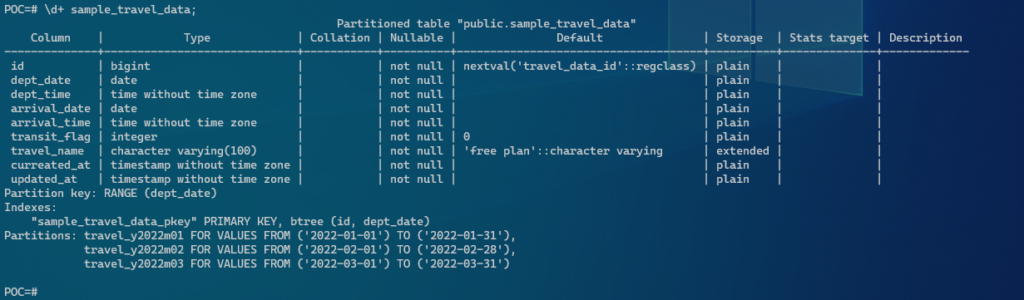
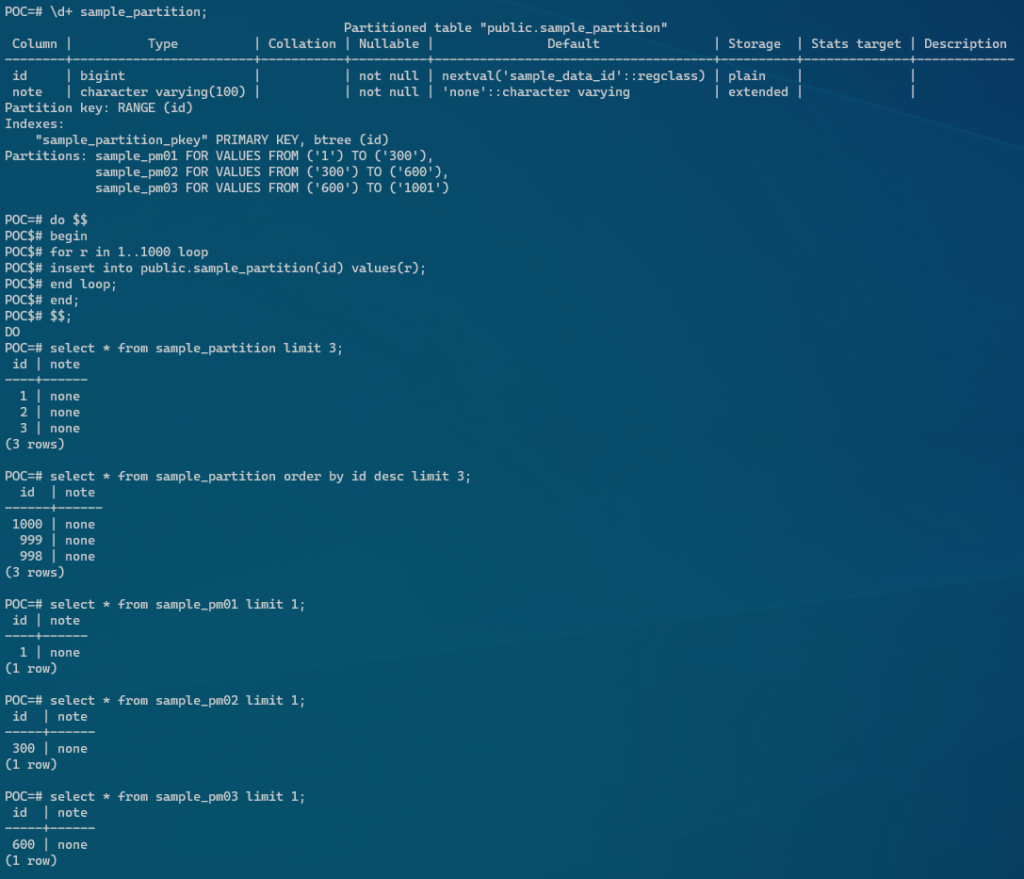
- データ分散状況の確認
/*** Database Objects ***/
CREATE SEQUENCE sample_data_id START 1;
CREATE TABLE sample_partition (
id bigint not null default nextval('sample_data_id'),
note varchar(100) not null default 'none',
PRIMARY KEY (id)
) PARTITION BY RANGE (id);
/*** Sample Partition ****/
CREATE TABLE sample_pm01 PARTITION OF sample_partition
FOR VALUES FROM (1) TO (300);
CREATE TABLE sample_pm02 PARTITION OF sample_partition
FOR VALUES FROM (300) TO (600);
CREATE TABLE sample_pm03 PARTITION OF sample_partition
FOR VALUES FROM (600) TO (1001);
/*** Loop Insert Dummy Data ***/
do $$
begin
for r in 1..1000 loop
insert into public.sample_partition(id) values(r);
end loop;
end;
$$;
上記で作成したサンプルテーブルにデータを流し込んだ結果
※備考: (上記サンプル処理では、Default値として設定したSequenceを無視してしまっているので、データ追加時にエラーになるので適宜処理や オブジェクト設計を考慮しましょう。)
POC=# select setval('sample_data_id',1, false);
setval
--------
1
(1 row)
POC=# insert into sample_partition(note) values('This is Sqeuence Test');
ERROR: duplicate key value violates unique constraint "sample_pm01_pkey"
DETAIL: Key (id)=(1) already exists.
POC=# select setval('sample_data_id',1001, false);
setval
--------
1001
(1 row)
POC=# CREATE TABLE sample_pm04 PARTITION OF sample_partition
POC-# FOR VALUES FROM (1001) TO (2001);
CREATE TABLE
POC=# insert into sample_partition(note) values('This is Sqeuence Test');
INSERT 0 1
POC=# select * from sample_partition order by id desc limit 3;
id | note
------+-----------------------
1001 | This is Sqeuence Test
1000 | none
999 | none
(3 rows)こんな感じであれば設定してあるSequecnceを使えますね。「本番環境で運用する時も、ここら辺はきちんと考慮しないといけませんね」
POC=# truncate table sample_partition;
TRUNCATE TABLE
POC=# select * from sample_partition;
id | note
----+------
(0 rows)
POC=# select setval('sample_data_id', 1, false);
setval
--------
1
(1 row)
POC=# do $$
POC$# begin
POC$# for r in 1..1000 loop
POC$# insert into public.sample_partition(note) values('パーティションへのデータ投入');
POC$# end loop;
POC$# end;
POC$# $$;
DO
POC=# select * from sample_partition limit 3;
id | note
----+------------------------------
1 | パーティションへのデータ投入
2 | パーティションへのデータ投入
3 | パーティションへのデータ投入
(3 rows)
POC=# select * from sample_partition order by id desc limit 3;
id | note
------+------------------------------
1000 | パーティションへのデータ投入
999 | パーティションへのデータ投入
998 | パーティションへのデータ投入
(3 rows)
POC=#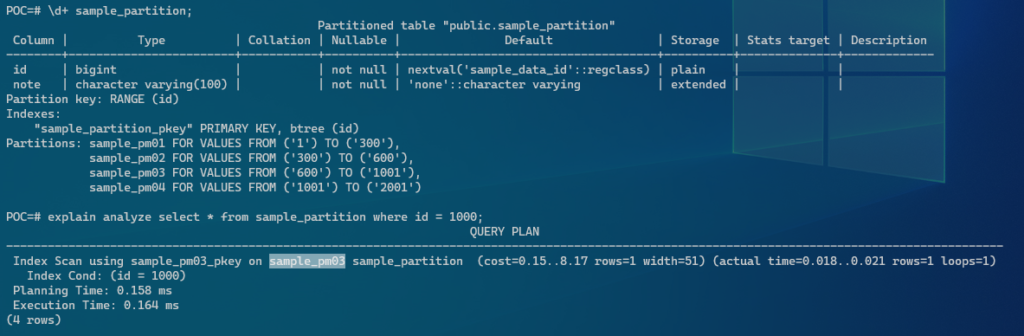
TableをTruncateする予定があれば、以下の様にSequenceのオーナーテーブルの設定も必要ですね。
POC=# alter sequence sample_data_id owned by sample_partition.id;
ALTER SEQUENCE
Time: 4.657 ms
POC=# \d+ sample_data_id;
Sequence "public.sample_data_id"
Type | Start | Minimum | Maximum | Increment | Cycles? | Cache
--------+-------+---------+---------------------+-----------+---------+-------
bigint | 1 | 1 | 9223372036854775807 | 1 | no | 1
Owned by: public.sample_partition.id
POC=# select * from sample_data_id;
last_value | log_cnt | is_called
------------+---------+-----------
1000 | 23 | t
(1 row)
Time: 1.088 ms
POC=# TRUNCATE TABLE sample_partition RESTART IDENTITY;
TRUNCATE TABLE
Time: 47.883 ms
POC=# select * from sample_data_id;
last_value | log_cnt | is_called
------------+---------+-----------
1 | 0 | f
(1 row)
Time: 1.400 ms
POC=# do $$
POC$# begin
POC$# for r in 1..50000 loop
POC$# insert into public.sample_partition(id) values(r);
POC$# end loop;
POC$# end;
POC$# $$;
DO
Time: 559.106 ms
POC=# select count(*) from sample_partition;
count
-------
50000
(1 row)
Time: 12.934 ms
POC=#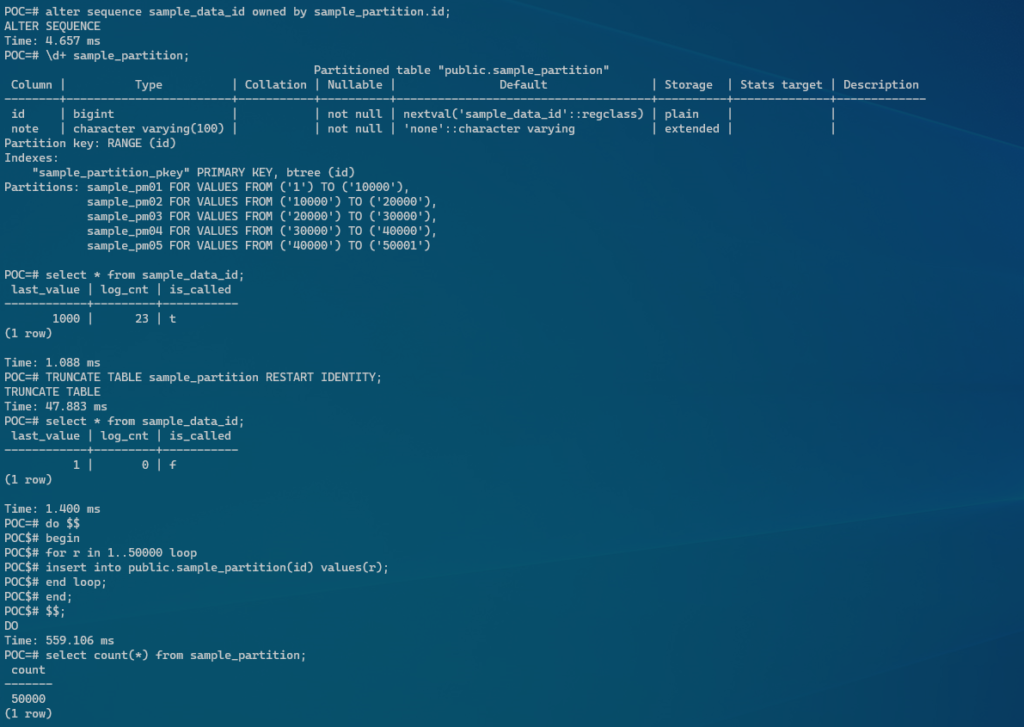
Comment: コメントを付けておくと自分以外の人も認識し易いかと思います。
POC=# \d+ sample_partition;
Partitioned table "public.sample_partition"
Column | Type | Collation | Nullable | Default | Storage | Stats target | Description
--------+------------------------+-----------+----------+-------------------------------------+----------+--------------+-------------
id | bigint | | not null | nextval('sample_data_id'::regclass) | plain | |
note | character varying(100) | | not null | 'none'::character varying | extended | |
Partition key: RANGE (id)
Indexes:
"sample_partition_pkey" PRIMARY KEY, btree (id)
Partitions: sample_pm01 FOR VALUES FROM ('1') TO ('10000'),
sample_pm02 FOR VALUES FROM ('10000') TO ('20000'),
sample_pm03 FOR VALUES FROM ('20000') TO ('30000'),
sample_pm04 FOR VALUES FROM ('30000') TO ('40000'),
sample_pm05 FOR VALUES FROM ('40000') TO ('50001')
POC=# comment on table sample_partition is 'partitionマスターテーブル';
COMMENT
POC=# comment on table sample_pm01 is 'partition子テーブル';
COMMENT
POC=# comment on table sample_pm02 is 'partition子テーブル';
COMMENT
POC=# comment on table sample_pm03 is 'partition子テーブル';
COMMENT
POC=# comment on table sample_pm04 is 'partition子テーブル';
COMMENT
POC=# comment on table sample_pm05 is 'partition子テーブル';
COMMENT
POC=# \dt+
List of relations
Schema | Name | Type | Owner | Persistence | Access method | Size | Description
--------+------------------------------------+-------------------+----------+-------------+---------------+------------+---------------------------
<SNIP>
public | sample_partition | partitioned table | postgres | permanent | | 0 bytes | partitionマスターテーブル
public | sample_pm01 | table | postgres | permanent | heap | 472 kB | partition子テーブル
public | sample_pm02 | table | postgres | permanent | heap | 472 kB | partition子テーブル
public | sample_pm03 | table | postgres | permanent | heap | 472 kB | partition子テーブル
public | sample_pm04 | table | postgres | permanent | heap | 472 kB | partition子テーブル
public | sample_pm05 | table | postgres | permanent | heap | 472 kB | partition子テーブル
<SNIP>
POC=#パーティションの制限事項 : COPY TOコマンド
COPY FROMには制限はありません。(パーティションテーブル、子パーティションテーブル共にOK)
-- パーティションテーブルでのCOPY TOコマンド
POC=# COPY sample_partition TO '/tmp/copy_20210305_sample_partition.sql';
ERROR: cannot copy from partitioned table "sample_partition"
HINT: Try the COPY (SELECT ...) TO variant.
POC=#
-- パーティション子テーブルでのCOPY TOコマンド
POC=# COPY sample_pm01 TO '/tmp/copy_sample_pm01.sql';
COPY 10000
POC=# COPY sample_pm02 TO '/tmp/copy_sample_pm02.sql';
COPY 10000
POC=# COPY sample_pm03 TO '/tmp/copy_sample_pm03.sql';
COPY 10000
POC=# COPY sample_pm04 TO '/tmp/copy_sample_pm04.sql';
COPY 10000
POC=# COPY sample_pm05 TO '/tmp/copy_sample_pm05.sql';
COPY 10000※ バージョンによっても制限が異なるので適宜マニュアルを確認して下さい。
MySQL Partition
MySQLでは、RANGE、LIST、HASH、KEYパーティショニングをサポートしています。
- RANGEパーティション
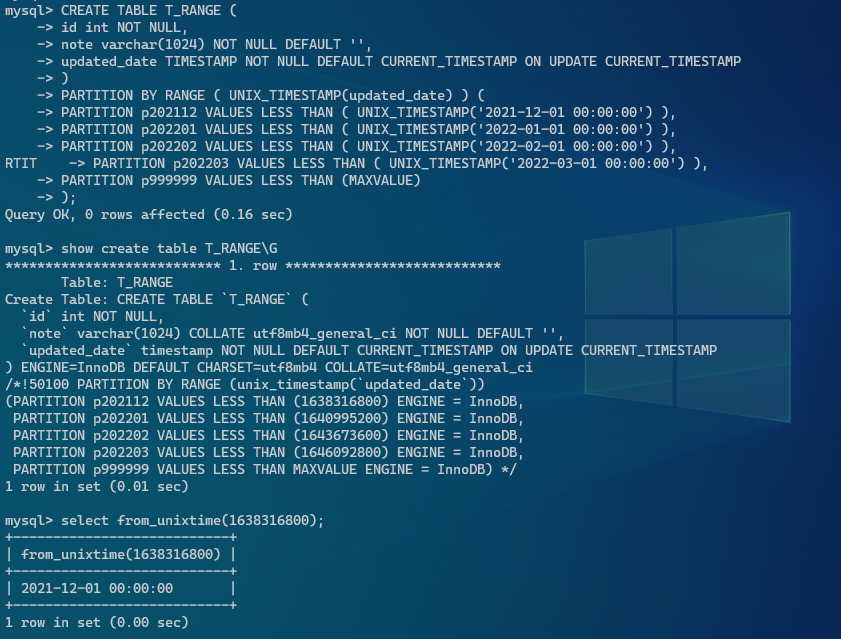
CREATE TABLE T_RANGE (
id int NOT NULL,
note varchar(1024) NOT NULL DEFAULT '',
updated_date TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
)
PARTITION BY RANGE ( UNIX_TIMESTAMP(updated_date) ) (
PARTITION p202112 VALUES LESS THAN ( UNIX_TIMESTAMP('2021-12-01 00:00:00') ),
PARTITION p202201 VALUES LESS THAN ( UNIX_TIMESTAMP('2022-01-01 00:00:00') ),
PARTITION p202202 VALUES LESS THAN ( UNIX_TIMESTAMP('2022-02-01 00:00:00') ),
PARTITION p202203 VALUES LESS THAN ( UNIX_TIMESTAMP('2022-03-01 00:00:00') ),
PARTITION p999999 VALUES LESS THAN (MAXVALUE)
);
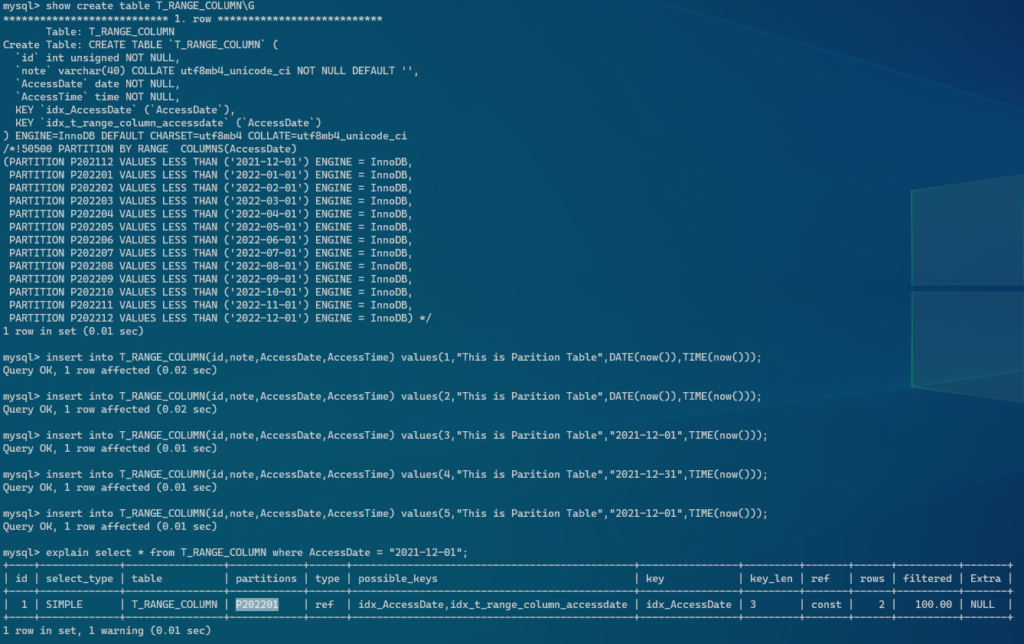
- RANGE COLUMNSパーティション
CREATE TABLE `T_RANGE_COLUMN` (
`id` int unsigned NOT NULL,
`note` varchar(40) NOT NULL DEFAULT '',
`AccessDate` date NOT NULL,
`AccessTime` time NOT NULL,
KEY `idx_AccessDate` (`AccessDate`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci
/*!50500 PARTITION BY RANGE COLUMNS(AccessDate)
(PARTITION P202112 VALUES LESS THAN ('2021-12-01') ENGINE = InnoDB,
PARTITION P202201 VALUES LESS THAN ('2022-01-01') ENGINE = InnoDB,
PARTITION P202202 VALUES LESS THAN ('2022-02-01') ENGINE = InnoDB,
PARTITION P202203 VALUES LESS THAN ('2022-03-01') ENGINE = InnoDB,
PARTITION P202204 VALUES LESS THAN ('2022-04-01') ENGINE = InnoDB,
PARTITION P202205 VALUES LESS THAN ('2022-05-01') ENGINE = InnoDB,
PARTITION P202206 VALUES LESS THAN ('2022-06-01') ENGINE = InnoDB,
PARTITION P202207 VALUES LESS THAN ('2022-07-01') ENGINE = InnoDB,
PARTITION P202208 VALUES LESS THAN ('2022-08-01') ENGINE = InnoDB,
PARTITION P202209 VALUES LESS THAN ('2022-09-01') ENGINE = InnoDB,
PARTITION P202210 VALUES LESS THAN ('2022-10-01') ENGINE = InnoDB,
PARTITION P202211 VALUES LESS THAN ('2022-11-01') ENGINE = InnoDB,
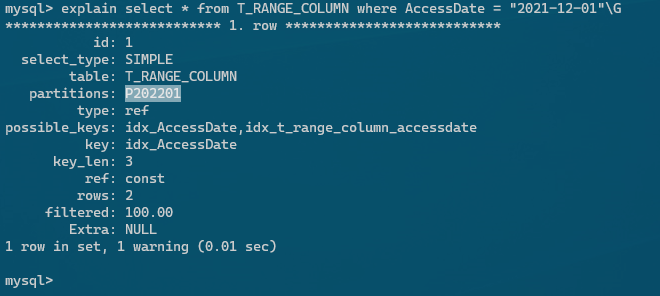
PARTITION P202212 VALUES LESS THAN ('2022-12-01') ENGINE = InnoDB) */- パーティション環境でのEXPLAIN
特定のパーティションからデータを読み込んでいる事が分かる。ここでは、p202202からデータを参照している。 インデックスを利用して、特定のデータをピンポイントで参照出来る場合はパーティションを組まないでも良いが、特定の月や日からまとめてデータを持ってくる場合は、インデックスが適切に利用出来ない事があるので、その場合は特定のパーティションからデータを参照する様にした方が高速化出来る。
mysql> CREATE TABLE T_RANGE (
-> id int NOT NULL,
-> note varchar(1024) NOT NULL DEFAULT '',
-> updated_date TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
-> )
-> PARTITION BY RANGE ( UNIX_TIMESTAMP(updated_date) ) (
-> PARTITION p202112 VALUES LESS THAN ( UNIX_TIMESTAMP('2021-12-01 00:00:00') ),
-> PARTITION p202201 VALUES LESS THAN ( UNIX_TIMESTAMP('2022-01-01 00:00:00') ),
-> PARTITION p202202 VALUES LESS THAN ( UNIX_TIMESTAMP('2022-02-01 00:00:00') ),
-> PARTITION p202203 VALUES LESS THAN ( UNIX_TIMESTAMP('2022-03-01 00:00:00') ),
-> PARTITION p999999 VALUES LESS THAN (MAXVALUE)
-> );
Query OK, 0 rows affected (0.15 sec)
mysql> insert into T_RANGE(id,note) values(1,"This is Parition Table");
Query OK, 1 row affected (0.01 sec)
mysql> insert into T_RANGE(id,note) values(2,"This is Parition Table");
Query OK, 1 row affected (0.01 sec)
mysql> insert into T_RANGE(id,note) values(3,"This is Parition Table");
Query OK, 1 row affected (0.01 sec)
mysql> insert into T_RANGE(id,note) values(4,"This is Parition Table");
Query OK, 1 row affected (0.01 sec)
mysql> insert into T_RANGE(id,note) values(5,"This is Parition Table");
Query OK, 1 row affected (0.01 sec)
mysql> select * from T_RANGE;
+----+------------------------+---------------------+
| id | note | updated_date |
+----+------------------------+---------------------+
| 1 | This is Parition Table | 2022-01-26 22:23:47 |
| 2 | This is Parition Table | 2022-01-26 22:23:59 |
| 3 | This is Parition Table | 2022-01-26 22:24:08 |
| 4 | This is Parition Table | 2022-01-26 22:24:12 |
| 5 | This is Parition Table | 2022-01-26 22:24:16 |
+----+------------------------+---------------------+
5 rows in set (0.00 sec)
mysql> explain select * from T_RANGE where updated_date > '2022-01-01' and updated_date < '2022-01-31'\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: T_RANGE
partitions: p202202
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 5
filtered: 20.00
Extra: Using where
1 row in set, 1 warning (0.00 sec)
mysql>パーティションテーブルとインデックスの利用状況
以下の例では、日付でパーティションを設定してデータを分割して且つインデックスで処理出来ています。その為、少ないデータをメモリーにロード出来ると同時にアクセスするファイルI/Oを最小限にする事が出来ています。
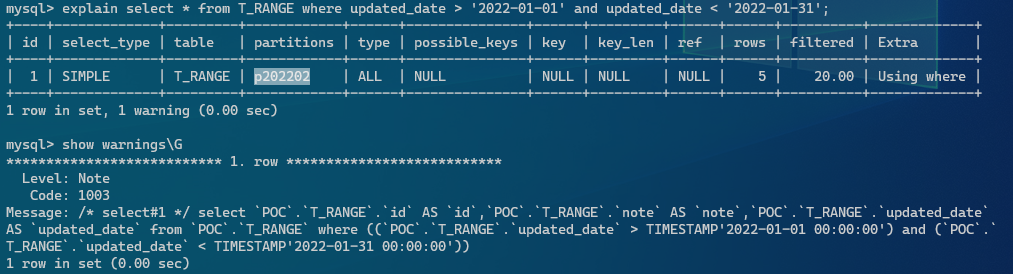
パーティションには制限事項も多いのでマニュアルをきちんと読んで、運用に入る前に検証しておきましょう。
備考:パーティションテーブルも他のオブジェクト同様にInformation_Schemaから確認可能です。
mysql> select TABLE_SCHEMA,TABLE_NAME,PARTITION_NAME,PARTITION_ORDINAL_POSITION,TABLE_ROWS from INFORMATION_SCHEMA.PARTITIONS where table_schema = 'POC';
+--------------+--------------------------------+----------------+----------------------------+------------+
| TABLE_SCHEMA | TABLE_NAME | PARTITION_NAME | PARTITION_ORDINAL_POSITION | TABLE_ROWS |
+--------------+--------------------------------+----------------+----------------------------+------------+
| POC | T1 | NULL | NULL | 0 |
| POC | T_JSON | NULL | NULL | 0 |
| POC | T_RANGE | p202112 | 1 | 0 |
| POC | T_RANGE | p202201 | 2 | 0 |
| POC | T_RANGE | p202202 | 3 | 0 |
| POC | T_RANGE | p202203 | 4 | 0 |
| POC | T_RANGE | p999999 | 5 | 0 |
| POC | members | NULL | NULL | 3 |
| POC | p11-10_12-jgd-g_busstop | NULL | NULL | 9832 |
| POC | p11-10_13-jgd-g_busstop | NULL | NULL | 8526 |
| POC | p11-10_14-jgd-g_busstop | NULL | NULL | 8521 |
| POC | p12-10-g_tourismresource_point | NULL | NULL | 2019 |
| POC | tourism_and_busstop | NULL | NULL | 29950 |
| POC | trip_generated_column_unquote | NULL | NULL | 3 |
| POC | zone_area | NULL | NULL | 0 |
+--------------+--------------------------------+----------------+----------------------------+------------+
15 rows in set (0.09 sec)
mysql> SELECT FILE_NAME FROM INFORMATION_SCHEMA.FILES
-> WHERE FILE_NAME LIKE '%#p#%' OR FILE_NAME LIKE '%#sp#%';
+-----------------------------+
| FILE_NAME |
+-----------------------------+
| ./POC/T_RANGE#p#p202112.ibd |
| ./POC/T_RANGE#p#p202201.ibd |
| ./POC/T_RANGE#p#p202202.ibd |
| ./POC/T_RANGE#p#p202203.ibd |
| ./POC/T_RANGE#p#p999999.ibd |
+-----------------------------+
5 rows in set (0.00 sec)
mysql>参照:
24.6.1 パーティショニングキー、主キー、および一意キー