MySQLにおける、文字コードと照合順序(COLLATION)
照合順序は文字列の比較やソート順のルールのことです。各キャラクタセットごとに照合順序が定義されています。文字コードは日本語、中国語、韓国語等であれば絵文字もサポートしている4byteのutf8mb4で良いでしょう。utf8は3byteですので、特殊文字や絵文字等などが格納出来ません。COLLATIONに関しては、それぞれのの違いを認識して利用して頂ければ良いかと思いますが、以前からの挙動を継承したい場合は、utf8mb4_general_ciを利用しても良いかもしれません。
mysql> show variables like '%char%';
+--------------------------+--------------------------------+
| Variable_name | Value |
+--------------------------+--------------------------------+
| character_set_client | utf8mb4 |
| character_set_connection | utf8mb4 |
| character_set_database | utf8mb4 |
| character_set_filesystem | binary |
| character_set_results | utf8mb4 |
| character_set_server | utf8mb4 |
| character_set_system | utf8mb3 |
| character_sets_dir | /usr/share/mysql-8.0/charsets/ |
+--------------------------+--------------------------------+
8 rows in set (0.00 sec)
mysql> SHOW VARIABLES LIKE 'collation%';
+----------------------+--------------------+
| Variable_name | Value |
+----------------------+--------------------+
| collation_connection | utf8mb4_0900_ai_ci |
| collation_database | utf8mb4_0900_ai_ci |
| collation_server | utf8mb4_general_ci |
+----------------------+--------------------+
3 rows in set (0.00 sec)
上記設定では、my.cnfで以下の様に設定しています。
shinya@DESKTOP-8BDL7KA:~/git/rdbms-docker/mysql/docker/mysql$ cat my.cnf
[mysqld]
character-set-server = utf8mb4
collation_server = utf8mb4_general_ci
max_allowed_packet = 8M
default_storage_engine = InnoDB
max_connections = 100
max_user_connections = 50
thread_cache_size = 100
# InnoDB
innodb_buffer_pool_size = 128M
# Compatibility
default_authentication_plugin=mysql_native_password
# Session variables
sort_buffer_size = 2M
tmp_table_size = 8M
read_buffer_size = 10M
read_rnd_buffer_size = 1M
join_buffer_size = 1M
max_heap_table_size = 8M
log_timestamps = SYSTEM
[client]
default-character-set = utf8mb4MySQL8.0のutf8mb4関連のCollationは以下の様な選択肢があります。
これからの中から、選択するのは難しいと思いますので使慣れているutf8mb4_general_ci, utf8mb4_0900_ai_ci, utf8mb4_0900_binあたりが使い勝手が良いかと思います。但し、要件はサービスに求められる構成によって異なるので適宜検討が必要です。
mysql> show collation like 'utf8mb4%';
+----------------------------+---------+-----+---------+----------+---------+---------------+
| Collation | Charset | Id | Default | Compiled | Sortlen | Pad_attribute |
+----------------------------+---------+-----+---------+----------+---------+---------------+
| utf8mb4_0900_ai_ci | utf8mb4 | 255 | Yes | Yes | 0 | NO PAD |
| utf8mb4_0900_as_ci | utf8mb4 | 305 | | Yes | 0 | NO PAD |
| utf8mb4_0900_as_cs | utf8mb4 | 278 | | Yes | 0 | NO PAD |
| utf8mb4_0900_bin | utf8mb4 | 309 | | Yes | 1 | NO PAD |
| utf8mb4_bin | utf8mb4 | 46 | | Yes | 1 | PAD SPACE |
| utf8mb4_croatian_ci | utf8mb4 | 245 | | Yes | 8 | PAD SPACE |
| utf8mb4_cs_0900_ai_ci | utf8mb4 | 266 | | Yes | 0 | NO PAD |
| utf8mb4_cs_0900_as_cs | utf8mb4 | 289 | | Yes | 0 | NO PAD |
| utf8mb4_czech_ci | utf8mb4 | 234 | | Yes | 8 | PAD SPACE |
| utf8mb4_danish_ci | utf8mb4 | 235 | | Yes | 8 | PAD SPACE |
| utf8mb4_da_0900_ai_ci | utf8mb4 | 267 | | Yes | 0 | NO PAD |
| utf8mb4_da_0900_as_cs | utf8mb4 | 290 | | Yes | 0 | NO PAD |
| utf8mb4_de_pb_0900_ai_ci | utf8mb4 | 256 | | Yes | 0 | NO PAD |
| utf8mb4_de_pb_0900_as_cs | utf8mb4 | 279 | | Yes | 0 | NO PAD |
| utf8mb4_eo_0900_ai_ci | utf8mb4 | 273 | | Yes | 0 | NO PAD |
| utf8mb4_eo_0900_as_cs | utf8mb4 | 296 | | Yes | 0 | NO PAD |
| utf8mb4_esperanto_ci | utf8mb4 | 241 | | Yes | 8 | PAD SPACE |
| utf8mb4_estonian_ci | utf8mb4 | 230 | | Yes | 8 | PAD SPACE |
| utf8mb4_es_0900_ai_ci | utf8mb4 | 263 | | Yes | 0 | NO PAD |
| utf8mb4_es_0900_as_cs | utf8mb4 | 286 | | Yes | 0 | NO PAD |
| utf8mb4_es_trad_0900_ai_ci | utf8mb4 | 270 | | Yes | 0 | NO PAD |
| utf8mb4_es_trad_0900_as_cs | utf8mb4 | 293 | | Yes | 0 | NO PAD |
| utf8mb4_et_0900_ai_ci | utf8mb4 | 262 | | Yes | 0 | NO PAD |
| utf8mb4_et_0900_as_cs | utf8mb4 | 285 | | Yes | 0 | NO PAD |
| utf8mb4_general_ci | utf8mb4 | 45 | | Yes | 1 | PAD SPACE |
| utf8mb4_german2_ci | utf8mb4 | 244 | | Yes | 8 | PAD SPACE |
| utf8mb4_hr_0900_ai_ci | utf8mb4 | 275 | | Yes | 0 | NO PAD |
| utf8mb4_hr_0900_as_cs | utf8mb4 | 298 | | Yes | 0 | NO PAD |
| utf8mb4_hungarian_ci | utf8mb4 | 242 | | Yes | 8 | PAD SPACE |
| utf8mb4_hu_0900_ai_ci | utf8mb4 | 274 | | Yes | 0 | NO PAD |
| utf8mb4_hu_0900_as_cs | utf8mb4 | 297 | | Yes | 0 | NO PAD |
| utf8mb4_icelandic_ci | utf8mb4 | 225 | | Yes | 8 | PAD SPACE |
| utf8mb4_is_0900_ai_ci | utf8mb4 | 257 | | Yes | 0 | NO PAD |
| utf8mb4_is_0900_as_cs | utf8mb4 | 280 | | Yes | 0 | NO PAD |
| utf8mb4_ja_0900_as_cs | utf8mb4 | 303 | | Yes | 0 | NO PAD |
| utf8mb4_ja_0900_as_cs_ks | utf8mb4 | 304 | | Yes | 24 | NO PAD |
| utf8mb4_latvian_ci | utf8mb4 | 226 | | Yes | 8 | PAD SPACE |
| utf8mb4_la_0900_ai_ci | utf8mb4 | 271 | | Yes | 0 | NO PAD |
| utf8mb4_la_0900_as_cs | utf8mb4 | 294 | | Yes | 0 | NO PAD |
| utf8mb4_lithuanian_ci | utf8mb4 | 236 | | Yes | 8 | PAD SPACE |
| utf8mb4_lt_0900_ai_ci | utf8mb4 | 268 | | Yes | 0 | NO PAD |
| utf8mb4_lt_0900_as_cs | utf8mb4 | 291 | | Yes | 0 | NO PAD |
| utf8mb4_lv_0900_ai_ci | utf8mb4 | 258 | | Yes | 0 | NO PAD |
| utf8mb4_lv_0900_as_cs | utf8mb4 | 281 | | Yes | 0 | NO PAD |
| utf8mb4_persian_ci | utf8mb4 | 240 | | Yes | 8 | PAD SPACE |
| utf8mb4_pl_0900_ai_ci | utf8mb4 | 261 | | Yes | 0 | NO PAD |
| utf8mb4_pl_0900_as_cs | utf8mb4 | 284 | | Yes | 0 | NO PAD |
| utf8mb4_polish_ci | utf8mb4 | 229 | | Yes | 8 | PAD SPACE |
| utf8mb4_romanian_ci | utf8mb4 | 227 | | Yes | 8 | PAD SPACE |
| utf8mb4_roman_ci | utf8mb4 | 239 | | Yes | 8 | PAD SPACE |
| utf8mb4_ro_0900_ai_ci | utf8mb4 | 259 | | Yes | 0 | NO PAD |
| utf8mb4_ro_0900_as_cs | utf8mb4 | 282 | | Yes | 0 | NO PAD |
| utf8mb4_ru_0900_ai_ci | utf8mb4 | 306 | | Yes | 0 | NO PAD |
| utf8mb4_ru_0900_as_cs | utf8mb4 | 307 | | Yes | 0 | NO PAD |
| utf8mb4_sinhala_ci | utf8mb4 | 243 | | Yes | 8 | PAD SPACE |
| utf8mb4_sk_0900_ai_ci | utf8mb4 | 269 | | Yes | 0 | NO PAD |
| utf8mb4_sk_0900_as_cs | utf8mb4 | 292 | | Yes | 0 | NO PAD |
| utf8mb4_slovak_ci | utf8mb4 | 237 | | Yes | 8 | PAD SPACE |
| utf8mb4_slovenian_ci | utf8mb4 | 228 | | Yes | 8 | PAD SPACE |
| utf8mb4_sl_0900_ai_ci | utf8mb4 | 260 | | Yes | 0 | NO PAD |
| utf8mb4_sl_0900_as_cs | utf8mb4 | 283 | | Yes | 0 | NO PAD |
| utf8mb4_spanish2_ci | utf8mb4 | 238 | | Yes | 8 | PAD SPACE |
| utf8mb4_spanish_ci | utf8mb4 | 231 | | Yes | 8 | PAD SPACE |
| utf8mb4_sv_0900_ai_ci | utf8mb4 | 264 | | Yes | 0 | NO PAD |
| utf8mb4_sv_0900_as_cs | utf8mb4 | 287 | | Yes | 0 | NO PAD |
| utf8mb4_swedish_ci | utf8mb4 | 232 | | Yes | 8 | PAD SPACE |
| utf8mb4_tr_0900_ai_ci | utf8mb4 | 265 | | Yes | 0 | NO PAD |
| utf8mb4_tr_0900_as_cs | utf8mb4 | 288 | | Yes | 0 | NO PAD |
| utf8mb4_turkish_ci | utf8mb4 | 233 | | Yes | 8 | PAD SPACE |
| utf8mb4_unicode_520_ci | utf8mb4 | 246 | | Yes | 8 | PAD SPACE |
| utf8mb4_unicode_ci | utf8mb4 | 224 | | Yes | 8 | PAD SPACE |
| utf8mb4_vietnamese_ci | utf8mb4 | 247 | | Yes | 8 | PAD SPACE |
| utf8mb4_vi_0900_ai_ci | utf8mb4 | 277 | | Yes | 0 | NO PAD |
| utf8mb4_vi_0900_as_cs | utf8mb4 | 300 | | Yes | 0 | NO PAD |
| utf8mb4_zh_0900_as_cs | utf8mb4 | 308 | | Yes | 0 | NO PAD |
+----------------------------+---------+-----+---------+----------+---------+---------------+
75 rows in set (0.00 sec)
Character Set やCollationによって、データの処理が変わってくるので意図した挙動にする為には、以下の様にCHARSETやCOLLATEで指定してあげる必要があります。指定しない場合はDefaultの設定が適用されます。
mysql> show create table T_utf8mb4_0900\G
*************************** 1. row ***************************
Table: T_utf8mb4_0900
Create Table: CREATE TABLE `T_utf8mb4_0900` (
`id` int NOT NULL AUTO_INCREMENT,
`moji` varchar(100) NOT NULL DEFAULT '-' COMMENT '文字コード',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
1 row in set (0.00 sec)
mysql> show create table T_utf8mb4_general\G
*************************** 1. row ***************************
Table: T_utf8mb4_general
Create Table: CREATE TABLE `T_utf8mb4_general` (
`id` int NOT NULL AUTO_INCREMENT,
`moji` varchar(100) COLLATE utf8mb4_general_ci NOT NULL DEFAULT '-' COMMENT '文字コード',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci
1 row in set (0.01 sec)
既存のテーブルの設定を変更する場合は以下の様にSQLを生成して実行すれば良いでしょう。
SELECT CONCAT("ALTER TABLE ",TABLE_SCHEMA,".",TABLE_NAME," CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci; ","ALTER TABLE ",TABLE_SCHEMA,".",TABLE_NAME," CONVERT TO CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci; ") AS alter_sql
FROM information_schema.TABLES where TABLE_SCHEMA = 'POC';
SET NAMES utf8mb4 COLLATE utf8mb4_general_ci;
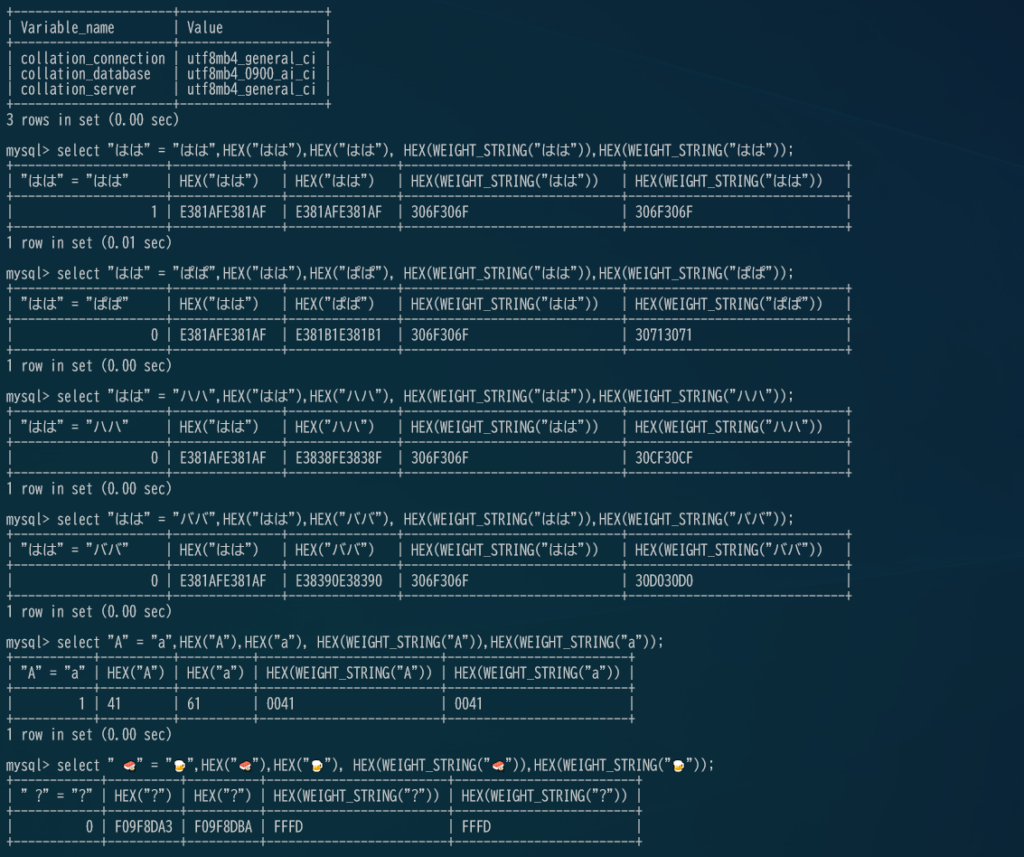
絵文字は区別出来ないけど、カタカナ、ひらがな等もきちんと識別出来ています。
mysql> SET NAMES utf8mb4 COLLATE utf8mb4_general_ci;
Query OK, 0 rows affected (0.00 sec)
mysql> SHOW VARIABLES LIKE 'collation%';
+----------------------+--------------------+
| Variable_name | Value |
+----------------------+--------------------+
| collation_connection | utf8mb4_general_ci |
| collation_database | utf8mb4_0900_ai_ci |
| collation_server | utf8mb4_general_ci |
+----------------------+--------------------+
3 rows in set (0.00 sec)
mysql> select "はは" = "はは",HEX("はは"),HEX("はは"), HEX(WEIGHT_STRING("はは")),HEX(WEIGHT_STRING("はは"))\G
*************************** 1. row ***************************
"はは" = "はは": 1
HEX("はは"): E381AFE381AF
HEX("はは"): E381AFE381AF
HEX(WEIGHT_STRING("はは")): 306F306F
HEX(WEIGHT_STRING("はは")): 306F306F
1 row in set (0.00 sec)
mysql> select "はは" = "ぱぱ",HEX("はは"),HEX("ぱぱ"), HEX(WEIGHT_STRING("はは")),HEX(WEIGHT_STRING("ぱぱ"))\G
*************************** 1. row ***************************
"はは" = "ぱぱ": 0
HEX("はは"): E381AFE381AF
HEX("ぱぱ"): E381B1E381B1
HEX(WEIGHT_STRING("はは")): 306F306F
HEX(WEIGHT_STRING("ぱぱ")): 30713071
1 row in set (0.00 sec)
mysql> select "はは" = "ハハ",HEX("はは"),HEX("ハハ"), HEX(WEIGHT_STRING("はは")),HEX(WEIGHT_STRING("ハハ"))\G
*************************** 1. row ***************************
"はは" = "ハハ": 0
HEX("はは"): E381AFE381AF
HEX("ハハ"): E3838FE3838F
HEX(WEIGHT_STRING("はは")): 306F306F
HEX(WEIGHT_STRING("ハハ")): 30CF30CF
1 row in set (0.00 sec)
mysql> select "はは" = "ババ",HEX("はは"),HEX("ババ"), HEX(WEIGHT_STRING("はは")),HEX(WEIGHT_STRING("ババ"))\G
*************************** 1. row ***************************
"はは" = "ババ": 0
HEX("はは"): E381AFE381AF
HEX("ババ"): E38390E38390
HEX(WEIGHT_STRING("はは")): 306F306F
HEX(WEIGHT_STRING("ババ")): 30D030D0
1 row in set (0.00 sec)
mysql> select "パパ" = "ババ",HEX("パパ"),HEX("ババ"), HEX(WEIGHT_STRING("パパ")),HEX(WEIGHT_STRING("ババ"))\G
*************************** 1. row ***************************
"パパ" = "ババ": 0
HEX("パパ"): E38391E38391
HEX("ババ"): E38390E38390
HEX(WEIGHT_STRING("パパ")): 30D130D1
HEX(WEIGHT_STRING("ババ")): 30D030D0
1 row in set (0.00 sec)
mysql> select "A" = "a",HEX("A"),HEX("a"), HEX(WEIGHT_STRING("A")),HEX(WEIGHT_STRING("a"))\G
*************************** 1. row ***************************
"A" = "a": 1
HEX("A"): 41
HEX("a"): 61
HEX(WEIGHT_STRING("A")): 0041
HEX(WEIGHT_STRING("a")): 0041
1 row in set (0.00 sec)
mysql> select " 🍣" = "🍺",HEX("🍣"),HEX("🍺"), HEX(WEIGHT_STRING("🍣")),HEX(WEIGHT_STRING("🍺"))\G
*************************** 1. row ***************************
" ?" = "?": 0
HEX("?"): F09F8DA3
HEX("?"): F09F8DBA
HEX(WEIGHT_STRING("?")): FFFD
HEX(WEIGHT_STRING("?")): FFFD
1 row in set (0.00 sec)
SET NAMES utf8mb4 COLLATE utf8mb4_0900_ai_ci;
絵文字は区別出来るけど、AやaをCase Insensitiveとして扱うのと同じ様にカタカナやひらがなも同じとして扱ってくれています。勿論、”はは”と”はな”は違うデータとして扱ってくれますが、”はは”と”ハハ”は同じとして扱います。
mysql> SET NAMES utf8mb4 COLLATE utf8mb4_0900_ai_ci;
Query OK, 0 rows affected (0.00 sec)
mysql> SHOW VARIABLES LIKE 'collation%';
+----------------------+--------------------+
| Variable_name | Value |
+----------------------+--------------------+
| collation_connection | utf8mb4_0900_ai_ci |
| collation_database | utf8mb4_0900_ai_ci |
| collation_server | utf8mb4_general_ci |
+----------------------+--------------------+
3 rows in set (0.00 sec)
mysql> select "はは" = "はは",HEX("はは"),HEX("はは"), HEX(WEIGHT_STRING("はは")),HEX(WEIGHT_STRING("はは"))\G
*************************** 1. row ***************************
"はは" = "はは": 1
HEX("はは"): E381AFE381AF
HEX("はは"): E381AFE381AF
HEX(WEIGHT_STRING("はは")): 3D743D74
HEX(WEIGHT_STRING("はは")): 3D743D74
1 row in set (0.00 sec)
mysql> select "はは" = "ぱぱ",HEX("はは"),HEX("ぱぱ"), HEX(WEIGHT_STRING("はは")),HEX(WEIGHT_STRING("ぱぱ"))\G
*************************** 1. row ***************************
"はは" = "ぱぱ": 1
HEX("はは"): E381AFE381AF
HEX("ぱぱ"): E381B1E381B1
HEX(WEIGHT_STRING("はは")): 3D743D74
HEX(WEIGHT_STRING("ぱぱ")): 3D743D74
1 row in set (0.00 sec)
mysql> select "はは" = "ハハ",HEX("はは"),HEX("ハハ"), HEX(WEIGHT_STRING("はは")),HEX(WEIGHT_STRING("ハハ"))\G
*************************** 1. row ***************************
"はは" = "ハハ": 1
HEX("はは"): E381AFE381AF
HEX("ハハ"): E3838FE3838F
HEX(WEIGHT_STRING("はは")): 3D743D74
HEX(WEIGHT_STRING("ハハ")): 3D743D74
1 row in set (0.00 sec)
mysql> select "はは" = "ババ",HEX("はは"),HEX("ババ"), HEX(WEIGHT_STRING("はは")),HEX(WEIGHT_STRING("ババ"))\G
*************************** 1. row ***************************
"はは" = "ババ": 1
HEX("はは"): E381AFE381AF
HEX("ババ"): E38390E38390
HEX(WEIGHT_STRING("はは")): 3D743D74
HEX(WEIGHT_STRING("ババ")): 3D743D74
1 row in set (0.00 sec)
mysql> select "パパ" = "ババ",HEX("パパ"),HEX("ババ"), HEX(WEIGHT_STRING("パパ")),HEX(WEIGHT_STRING("ババ"))\G
*************************** 1. row ***************************
"パパ" = "ババ": 1
HEX("パパ"): E38391E38391
HEX("ババ"): E38390E38390
HEX(WEIGHT_STRING("パパ")): 3D743D74
HEX(WEIGHT_STRING("ババ")): 3D743D74
1 row in set (0.00 sec)
mysql> select "A" = "a",HEX("A"),HEX("a"), HEX(WEIGHT_STRING("A")),HEX(WEIGHT_STRING("a"))\G
*************************** 1. row ***************************
"A" = "a": 1
HEX("A"): 41
HEX("a"): 61
HEX(WEIGHT_STRING("A")): 1C47
HEX(WEIGHT_STRING("a")): 1C47
1 row in set (0.00 sec)
mysql> select " 🍣" = "🍺",HEX("🍣"),HEX("🍺"), HEX(WEIGHT_STRING("🍣")),HEX(WEIGHT_STRING("🍺"))\G
*************************** 1. row ***************************
" ?" = "?": 0
HEX("?"): F09F8DA3
HEX("?"): F09F8DBA
HEX(WEIGHT_STRING("?")): 130C
HEX(WEIGHT_STRING("?")): 1323
1 row in set (0.00 sec)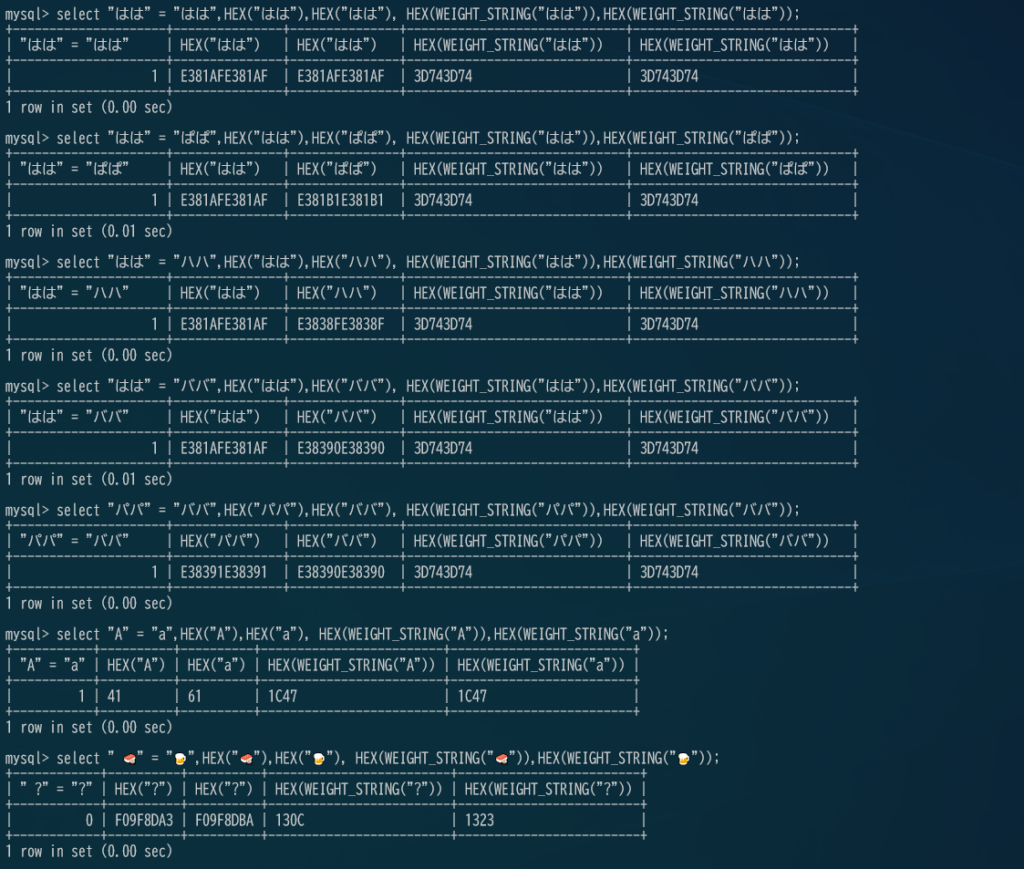
備考:MySQLのuserテーブルを確認頂くと分かり易いと思いますが、以下の様に列単位でも文字コードや照合順を指定可能です。パスワードが入る、authentication_stringに関しては大文字小文字をきちんと区別出来るutf8_binになっている事も確認する事が出来ます。
mysql> show create table user\G
*************************** 1. row ***************************
Table: user
Create Table: CREATE TABLE `user` (
`Host` char(255) CHARACTER SET ascii COLLATE ascii_general_ci NOT NULL DEFAULT '',
`User` char(32) CHARACTER SET utf8 COLLATE utf8_bin NOT NULL DEFAULT '',
`Select_priv` enum('N','Y') CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL DEFAULT 'N',
`Insert_priv` enum('N','Y') CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL DEFAULT 'N',
`Update_priv` enum('N','Y') CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL DEFAULT 'N',
`Delete_priv` enum('N','Y') CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL DEFAULT 'N',
`Create_priv` enum('N','Y') CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL DEFAULT 'N',
`Drop_priv` enum('N','Y') CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL DEFAULT 'N',
`Reload_priv` enum('N','Y') CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL DEFAULT 'N',
`Shutdown_priv` enum('N','Y') CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL DEFAULT 'N',
`Process_priv` enum('N','Y') CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL DEFAULT 'N',
`File_priv` enum('N','Y') CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL DEFAULT 'N',
`Grant_priv` enum('N','Y') CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL DEFAULT 'N',
`References_priv` enum('N','Y') CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL DEFAULT 'N',
`Index_priv` enum('N','Y') CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL DEFAULT 'N',
`Alter_priv` enum('N','Y') CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL DEFAULT 'N',
`Show_db_priv` enum('N','Y') CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL DEFAULT 'N',
`Super_priv` enum('N','Y') CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL DEFAULT 'N',
`Create_tmp_table_priv` enum('N','Y') CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL DEFAULT 'N',
`Lock_tables_priv` enum('N','Y') CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL DEFAULT 'N',
`Execute_priv` enum('N','Y') CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL DEFAULT 'N',
`Repl_slave_priv` enum('N','Y') CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL DEFAULT 'N',
`Repl_client_priv` enum('N','Y') CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL DEFAULT 'N',
`Create_view_priv` enum('N','Y') CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL DEFAULT 'N',
`Show_view_priv` enum('N','Y') CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL DEFAULT 'N',
`Create_routine_priv` enum('N','Y') CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL DEFAULT 'N',
`Alter_routine_priv` enum('N','Y') CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL DEFAULT 'N',
`Create_user_priv` enum('N','Y') CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL DEFAULT 'N',
`Event_priv` enum('N','Y') CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL DEFAULT 'N',
`Trigger_priv` enum('N','Y') CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL DEFAULT 'N',
`Create_tablespace_priv` enum('N','Y') CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL DEFAULT 'N',
`ssl_type` enum('','ANY','X509','SPECIFIED') CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL DEFAULT '',
`ssl_cipher` blob NOT NULL,
`x509_issuer` blob NOT NULL,
`x509_subject` blob NOT NULL,
`max_questions` int unsigned NOT NULL DEFAULT '0',
`max_updates` int unsigned NOT NULL DEFAULT '0',
`max_connections` int unsigned NOT NULL DEFAULT '0',
`max_user_connections` int unsigned NOT NULL DEFAULT '0',
`plugin` char(64) CHARACTER SET utf8 COLLATE utf8_bin NOT NULL DEFAULT 'caching_sha2_password',
`authentication_string` text CHARACTER SET utf8 COLLATE utf8_bin,
`password_expired` enum('N','Y') CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL DEFAULT 'N',
`password_last_changed` timestamp NULL DEFAULT NULL,
`password_lifetime` smallint unsigned DEFAULT NULL,
`account_locked` enum('N','Y') CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL DEFAULT 'N',
`Create_role_priv` enum('N','Y') CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL DEFAULT 'N',
`Drop_role_priv` enum('N','Y') CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL DEFAULT 'N',
`Password_reuse_history` smallint unsigned DEFAULT NULL,
`Password_reuse_time` smallint unsigned DEFAULT NULL,
`Password_require_current` enum('N','Y') CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL,
`User_attributes` json DEFAULT NULL,
PRIMARY KEY (`Host`,`User`)
) /*!50100 TABLESPACE `mysql` */ ENGINE=InnoDB DEFAULT CHARSET=utf8mb3 COLLATE=utf8_bin STATS_PERSISTENT=0 ROW_FORMAT=DYNAMIC COMMENT='Users and global privileges'
1 row in set (0.00 sec)
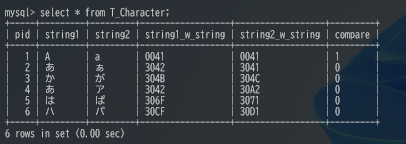
mysql>生成列の活用:自動的に値を比較する事も可能
mysql> CREATE TABLE `T_Character` (
-> `pid` int(10) unsigned NOT NULL AUTO_INCREMENT,
-> `string1` char(1) DEFAULT NULL,
-> `string2` char(1) DEFAULT NULL,
-> `string1_w_string` char(4) GENERATED ALWAYS AS (hex(weight_string(`string1`))) VIRTUAL,
-> `string2_w_string` char(4) GENERATED ALWAYS AS (hex(weight_string(`string2`))) VIRTUAL,
-> `compare` char(1) GENERATED ALWAYS AS ((`string1` = `string2`)) VIRTUAL,
-> PRIMARY KEY (`pid`)
-> ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci;
Query OK, 0 rows affected, 1 warning (0.07 sec)
mysql> insert into T_Character(string1,string2) values('A','a');
Query OK, 1 row affected (0.02 sec)
mysql> insert into T_Character(string1,string2) values('あ','ぁ');
Query OK, 1 row affected (0.01 sec)
mysql> insert into T_Character(string1,string2) values('か','が');
Query OK, 1 row affected (0.01 sec)
mysql> insert into T_Character(string1,string2) values('あ','ア');
Query OK, 1 row affected (0.02 sec)
mysql> insert into T_Character(string1,string2) values('は','ぱ');
Query OK, 1 row affected (0.02 sec)
mysql> insert into T_Character(string1,string2) values('ハ','パ');
Query OK, 1 row affected (0.02 sec)
mysql> select * from T_Character;
+-----+---------+---------+------------------+------------------+---------+
| pid | string1 | string2 | string1_w_string | string2_w_string | compare |
+-----+---------+---------+------------------+------------------+---------+
| 1 | A | a | 0041 | 0041 | 1 |
| 2 | あ | ぁ | 3042 | 3041 | 0 |
| 3 | か | が | 304B | 304C | 0 |
| 4 | あ | ア | 3042 | 30A2 | 0 |
| 5 | は | ぱ | 306F | 3071 | 0 |
| 6 | ハ | パ | 30CF | 30D1 | 0 |
+-----+---------+---------+------------------+------------------+---------+
6 rows in set (0.00 sec)
MySQL8.0についてutf8とutf8mb4の違いについて
補足:Default Collationを変更する場合
MySQL8.0にした場合にDefault Collationの違いで困るケースも多いかと思います。そんな時は、以下の様に設定を変更されるのが良いかと思います。
mysql> show variables like '%collation%';
+-------------------------------+--------------------+
| Variable_name | Value |
+-------------------------------+--------------------+
| collation_connection | utf8mb4_0900_ai_ci |
| collation_database | utf8mb3_general_ci |
| collation_server | utf8mb4_general_ci |
| default_collation_for_utf8mb4 | utf8mb4_0900_ai_ci |
+-------------------------------+--------------------+
4 rows in set (0.00 sec)
mysql> SET PERSIST collation_connection="utf8mb4_general_ci";
Query OK, 0 rows affected (0.00 sec)
mysql> SET PERSIST collation_database="utf8mb4_general_ci";
Query OK, 0 rows affected, 1 warning (0.00 sec)
mysql> SET PERSIST collation_server="utf8mb4_general_ci";
Query OK, 0 rows affected (0.00 sec)
mysql> SET PERSIST default_collation_for_utf8mb4="utf8mb4_general_ci";
Query OK, 0 rows affected, 1 warning (0.00 sec)
mysql> show global variables like '%collation%';
+-------------------------------+--------------------+
| Variable_name | Value |
+-------------------------------+--------------------+
| collation_connection | utf8mb4_general_ci |
| collation_database | utf8mb4_general_ci |
| collation_server | utf8mb4_general_ci |
| default_collation_for_utf8mb4 | utf8mb4_general_ci |
+-------------------------------+--------------------+
4 rows in set (0.00 sec)北川さんの此方の記事”MySQLのデフォルトcollationの注意点”も非常に参考になるかと思います。
既存データベースやテーブルを変換する場合
mysql> show create database POC\G
*************************** 1. row ***************************
Database: POC
Create Database: CREATE DATABASE `POC` /*!40100 DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci */ /*!80016 DEFAULT ENCRYPTION='N' */
1 row in set (0.00 sec)
mysql> alter database POC COLLATE utf8mb4_general_ci;
Query OK, 1 row affected (0.01 sec)
mysql> show create database POC\G
*************************** 1. row ***************************
Database: POC
Create Database: CREATE DATABASE `POC` /*!40100 DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci */ /*!80016 DEFAULT ENCRYPTION='N' */
1 row in set (0.00 sec)
mysql> show tables;
+--------------------------------+
| Tables_in_POC |
+--------------------------------+
| p12-10-g_tourismresource_point |
+--------------------------------+
1 row in set (0.01 sec)
mysql> show create table `p12-10-g_tourismresource_point`\G
*************************** 1. row ***************************
Table: p12-10-g_tourismresource_point
Create Table: CREATE TABLE `p12-10-g_tourismresource_point` (
`gid` bigint unsigned NOT NULL AUTO_INCREMENT,
`p12_001` varchar(14) DEFAULT NULL,
`p12_002` varchar(29) DEFAULT NULL,
`p12_003` varchar(52) DEFAULT NULL,
`p12_004` varchar(16) DEFAULT NULL,
`geom` point /*!80003 SRID 4612 */ DEFAULT NULL,
PRIMARY KEY (`gid`),
UNIQUE KEY `gid` (`gid`)
) ENGINE=InnoDB AUTO_INCREMENT=2020 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
1 row in set (0.00 sec)
mysql> ALTER TABLE `p12-10-g_tourismresource_point` CONVERT TO CHARACTER SET 'utf8mb4' COLLATE utf8mb4_general_ci;
Query OK, 0 rows affected (0.19 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> show create table `p12-10-g_tourismresource_point`\G
*************************** 1. row ***************************
Table: p12-10-g_tourismresource_point
Create Table: CREATE TABLE `p12-10-g_tourismresource_point` (
`gid` bigint unsigned NOT NULL AUTO_INCREMENT,
`p12_001` varchar(14) COLLATE utf8mb4_general_ci DEFAULT NULL,
`p12_002` varchar(29) COLLATE utf8mb4_general_ci DEFAULT NULL,
`p12_003` varchar(52) COLLATE utf8mb4_general_ci DEFAULT NULL,
`p12_004` varchar(16) COLLATE utf8mb4_general_ci DEFAULT NULL,
`geom` point /*!80003 SRID 4612 */ DEFAULT NULL,
PRIMARY KEY (`gid`),
UNIQUE KEY `gid` (`gid`)
) ENGINE=InnoDB AUTO_INCREMENT=2020 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci
1 row in set (0.00 sec)PostgreSQLにおける、文字コードと照合順序(COLLATION)
文字セット
デフォルトの文字セットは、initdbを使用したPostgreSQLデータベースクラスタの初期化時に決定されます。 これは、データベースを作成する時に上書きすることができるので、異なる文字セットを使用した複数のデータベースを持つことができます。それぞれのデータベースの文字セットがサーバのLC_CTYPE(文字分類)およびLC_COLLATE(文字列並び替え順序)ロケール設定と互換性がなくてはいけないことがあげられます。 CもしくはPOSIXロケール設定の場合、どのような文字セットも許可されています。 しかし、libcが提供する他のロケール設定の場合、正しく動作する文字セットはひとつだけとなります。
23.3. 文字セットサポート
照合順序
照合順序機能は、ソート順番と列ごともしくは操作ごとのデータの文字区別の振る舞いを指定することを可能にします。 これにより、作成後のデータベースのLC_COLLATEとLC_CTYPEの設定が変更できない制限が緩和されます。
23.2. 照合順序サポート
文字コードや照合順序を指定してデータベースを作成するには以下の様にCREATE文で指定します。
create database poc owner 'postgres' encoding 'UTF8' lc_collate 'ja_JP.UTF-8' lc_ctype 'ja_JP.UTF-8' template 'template0';以下の様にlやl+等のコマンドで各データベースがどのように設定されているか確認する事が可能です。
pocdb=# \l
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges
--------------+----------+----------+-------------+-------------+-----------------------
analyze_db | postgres | UTF8 | ja_JP.UTF-8 | ja_JP.UTF-8 | =Tc/postgres +
| | | | | postgres=CTc/postgres+
| | | | | poc=CTc/postgres
pocdb | poc | UTF8 | ja_JP.UTF-8 | ja_JP.UTF-8 |
postgres | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 |
template0 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =c/postgres +
| | | | | postgres=CTc/postgres
template1 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =c/postgres +
| | | | | postgres=CTc/postgres
(5 rows)
例)こちらのDocker環境ではCollate,CtypeにCを利用しています。
- インスタンス設定
POC=# SELECT name, setting, context FROM pg_settings WHERE name LIKE 'lc%';
name | setting | context
-------------+---------+-----------
lc_collate | C | internal
lc_ctype | C | internal
lc_messages | C | superuser
lc_monetary | C | user
lc_numeric | C | user
lc_time | C | user
(6 rows)- DB設定
POC=# \l+
List of databases
-[ RECORD 1 ]-----+-------------------------------------------
Name | POC
Owner | postgres
Encoding | UTF8
Collate | C
Ctype | C
Access privileges |
Size | 262 MB
Tablespace | pg_default
Description |
-[ RECORD 2 ]-----+-------------------------------------------
Name | postgres
Owner | postgres
Encoding | UTF8
Collate | C
Ctype | C
Access privileges |
Size | 7901 kB
Tablespace | pg_default
Description | default administrative connection database
-[ RECORD 3 ]-----+-------------------------------------------
Name | template0
Owner | postgres
Encoding | UTF8
Collate | C
Ctype | C
Access privileges | =c/postgres +
| postgres=CTc/postgres
Size | 7753 kB
Tablespace | pg_default
Description | unmodifiable empty database
-[ RECORD 4 ]-----+-------------------------------------------
Name | template1
Owner | postgres
Encoding | UTF8
Collate | C
Ctype | C
Access privileges | =c/postgres +
| postgres=CTc/postgres
Size | 7753 kB
Tablespace | pg_default
Description | default template for new databases
照合順序
“pg_collation”か”\dOS+”で利用可能なロケールを調べる事が可能です。
select * from pg_collation;
すべてのプラットフォーム上でdefault、CそしてPOSIXという名称の照合順序が 利用できます。 オペレーティングシステムによっては追加の照合順序が利用可能な場合もあります。 default照合順序は、データベース作成時にLC_COLLATE値とLC_CTYPE値を 選択します。CとPOSIX照合順序は共に「traditional C」の動作を指定します。 これはASCII文字の「A」から「Z」を文字として扱い、ソート順は厳密な文字コードのバイト値によります。加えて、エンコーディングUTF8では、SQL標準の照合順序名ucs_basicが利用できます。 ucs_basicはCと同等のもので、ソート順はUnicodeのコードポイントです。
23.2.2.1. 標準の照合順序
エンコード方式変換関数
POC=# select oid,conname,contoencoding,conproc,condefault from pg_conversion where conname like 'utf8%';
oid | conname | contoencoding | conproc | condefault
------+------------------------+---------------+------------------------+------------
4453 | utf8_to_big5 | 36 | utf8_to_big5 | t
4454 | utf8_to_koi8_r | 22 | utf8_to_koi8r | t
4456 | utf8_to_koi8_u | 34 | utf8_to_koi8u | t
4458 | utf8_to_windows_866 | 20 | utf8_to_win | t
4460 | utf8_to_windows_874 | 21 | utf8_to_win | t
4462 | utf8_to_windows_1250 | 29 | utf8_to_win | t
4464 | utf8_to_windows_1251 | 23 | utf8_to_win | t
4466 | utf8_to_windows_1252 | 24 | utf8_to_win | t
4468 | utf8_to_windows_1253 | 30 | utf8_to_win | t
4470 | utf8_to_windows_1254 | 31 | utf8_to_win | t
4472 | utf8_to_windows_1255 | 32 | utf8_to_win | t
4474 | utf8_to_windows_1256 | 18 | utf8_to_win | t
4476 | utf8_to_windows_1257 | 33 | utf8_to_win | t
4478 | utf8_to_windows_1258 | 19 | utf8_to_win | t
4481 | utf8_to_euc_cn | 2 | utf8_to_euc_cn | t
4483 | utf8_to_euc_jp | 1 | utf8_to_euc_jp | t
4485 | utf8_to_euc_kr | 3 | utf8_to_euc_kr | t
4487 | utf8_to_euc_tw | 4 | utf8_to_euc_tw | t
4489 | utf8_to_gb18030 | 39 | utf8_to_gb18030 | t
4491 | utf8_to_gbk | 37 | utf8_to_gbk | t
4492 | utf8_to_iso_8859_2 | 9 | utf8_to_iso8859 | t
4494 | utf8_to_iso_8859_3 | 10 | utf8_to_iso8859 | t
4496 | utf8_to_iso_8859_4 | 11 | utf8_to_iso8859 | t
4498 | utf8_to_iso_8859_9 | 12 | utf8_to_iso8859 | t
4500 | utf8_to_iso_8859_10 | 13 | utf8_to_iso8859 | t
4502 | utf8_to_iso_8859_13 | 14 | utf8_to_iso8859 | t
4504 | utf8_to_iso_8859_14 | 15 | utf8_to_iso8859 | t
4506 | utf8_to_iso_8859_15 | 16 | utf8_to_iso8859 | t
4508 | utf8_to_iso_8859_16 | 17 | utf8_to_iso8859 | t
4510 | utf8_to_iso_8859_5 | 25 | utf8_to_iso8859 | t
4512 | utf8_to_iso_8859_6 | 26 | utf8_to_iso8859 | t
4514 | utf8_to_iso_8859_7 | 27 | utf8_to_iso8859 | t
4516 | utf8_to_iso_8859_8 | 28 | utf8_to_iso8859 | t
4519 | utf8_to_iso_8859_1 | 8 | utf8_to_iso8859_1 | t
4521 | utf8_to_johab | 40 | utf8_to_johab | t
4523 | utf8_to_sjis | 35 | utf8_to_sjis | t
4525 | utf8_to_uhc | 38 | utf8_to_uhc | t
4527 | utf8_to_euc_jis_2004 | 5 | utf8_to_euc_jis_2004 | t
4529 | utf8_to_shift_jis_2004 | 41 | utf8_to_shift_jis_2004 | t
(39 rows)
サーバー側とクライアントの文字コードはMySQLの時も常に同じにしておきましょう。意図しない挙動や、文字の変換等でIndexが適切に利用出来ない等のケースが発生する可能性があります。
POC=# SHOW client_encoding;
client_encoding
-----------------
UTF8
(1 row)参照:23.3.3. サーバ・クライアント間の自動文字セット変換
照合順序機能は、ソート順番と列ごともしくは操作ごとのデータの文字区別の振る舞いを指定することを可能にします。 これにより、作成後のデータベースのLC_COLLATEとLC_CTYPEの設定が変更出来ない場合においても、以下の様に対応する事が可能です。MySQLの列毎のCOLLATION設定と同様かと思います。PostgreSQL10まではlibcに依存しているja_JPを利用していましたが、PostgreSQL10以降では、ja-x-icuなどが日本語を最適にソートしてくれるとの事です。但し、データベース単位ではサポートされていないとの事でした。 データベース単位では、EncodingがUTF8でja_JP.UTF-8やCをCOLLATEやCTYPEに利用して、テーブル単位で必要に応じてja-x-icu等を利用する方法等でも良いのかもしれません。
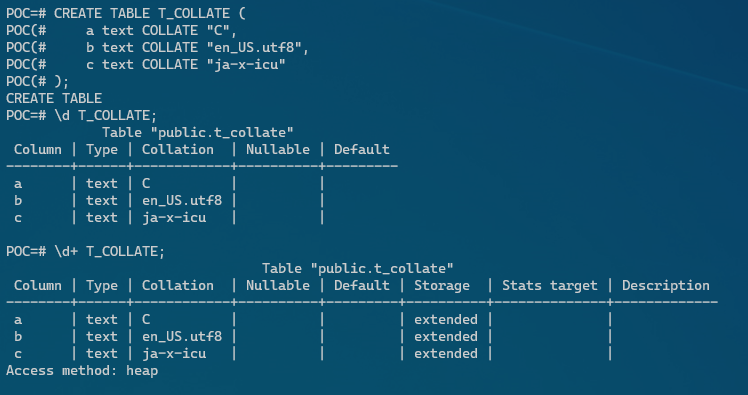
POC=# CREATE TABLE T_COLLATE (
POC(# a text COLLATE "C",
POC(# b text COLLATE "en_US.utf8",
POC(# c text COLLATE "ja-x-icu"
POC(# );
CREATE TABLE
POC=# \d+ T_COLLATE;
Table "public.t_collate"
Column | Type | Collation | Nullable | Default | Storage | Stats target | Description
--------+------+------------+----------+---------+----------+--------------+-------------
a | text | C | | | extended | |
b | text | en_US.utf8 | | | extended | |
c | text | ja-x-icu | | | extended | |
Access method: heap
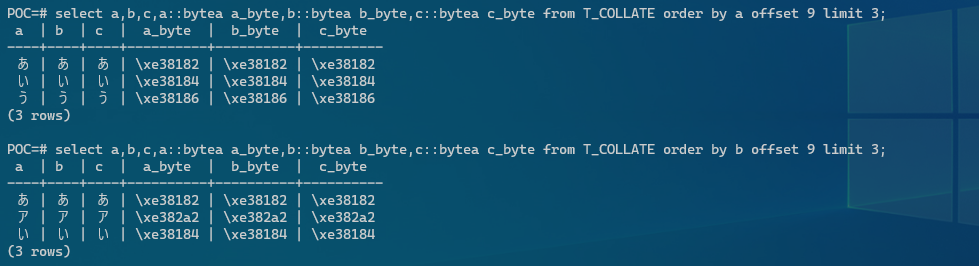
POC=#上記のテーブルに対してデータを登録してソートすると、以下の様にCOLLATIONによってソート順が異なる事が把握する事が出来ます。aはCollationがC、bはCollationがen_US.utf8, cはCollationがja-x-icu。
POC=# insert into T_COLLATE(a,b,c) values(1,1,1);
INSERT 0 1
POC=# insert into T_COLLATE(a,b,c) values(2,2,2);
INSERT 0 1
POC=# insert into T_COLLATE(a,b,c) values(3,3,3);
INSERT 0 1
POC=# insert into T_COLLATE(a,b,c) values('A','A','A');
INSERT 0 1
POC=# insert into T_COLLATE(a,b,c) values('B','B','B');
INSERT 0 1
POC=# insert into T_COLLATE(a,b,c) values('C','C','C');
INSERT 0 1
POC=# insert into T_COLLATE(a,b,c) values('a','a','a');
INSERT 0 1
POC=# insert into T_COLLATE(a,b,c) values('b','b','b');
INSERT 0 1
POC=# insert into T_COLLATE(a,b,c) values('c','c','c');
INSERT 0 1
POC=# insert into T_COLLATE(a,b,c) values('あ','あ','あ');
INSERT 0 1
POC=# insert into T_COLLATE(a,b,c) values('い','い','い');
INSERT 0 1
POC=# insert into T_COLLATE(a,b,c) values('う','う','う');
INSERT 0 1
POC=# insert into T_COLLATE(a,b,c) values('ア','ア','ア');
INSERT 0 1
POC=# insert into T_COLLATE(a,b,c) values('イ','イ','イ');
INSERT 0 1
POC=# insert into T_COLLATE(a,b,c) values('ウ','ウ','ウ');
INSERT 0 1
POC=# select a,b,c,a::bytea a_byte,b::bytea b_byte,c::bytea c_byte from T_COLLATE order by a;
a | b | c | a_byte | b_byte | c_byte
----+----+----+----------+----------+----------
1 | 1 | 1 | \x31 | \x31 | \x31
2 | 2 | 2 | \x32 | \x32 | \x32
3 | 3 | 3 | \x33 | \x33 | \x33
A | A | A | \x41 | \x41 | \x41
B | B | B | \x42 | \x42 | \x42
C | C | C | \x43 | \x43 | \x43
a | a | a | \x61 | \x61 | \x61
b | b | b | \x62 | \x62 | \x62
c | c | c | \x63 | \x63 | \x63
あ | あ | あ | \xe38182 | \xe38182 | \xe38182
い | い | い | \xe38184 | \xe38184 | \xe38184
う | う | う | \xe38186 | \xe38186 | \xe38186
ア | ア | ア | \xe382a2 | \xe382a2 | \xe382a2
イ | イ | イ | \xe382a4 | \xe382a4 | \xe382a4
ウ | ウ | ウ | \xe382a6 | \xe382a6 | \xe382a6
(15 rows)
POC=# select a,b,c,a::bytea a_byte,b::bytea b_byte,c::bytea c_byte from T_COLLATE order by b;
a | b | c | a_byte | b_byte | c_byte
----+----+----+----------+----------+----------
1 | 1 | 1 | \x31 | \x31 | \x31
2 | 2 | 2 | \x32 | \x32 | \x32
3 | 3 | 3 | \x33 | \x33 | \x33
a | a | a | \x61 | \x61 | \x61
A | A | A | \x41 | \x41 | \x41
b | b | b | \x62 | \x62 | \x62
B | B | B | \x42 | \x42 | \x42
c | c | c | \x63 | \x63 | \x63
C | C | C | \x43 | \x43 | \x43
あ | あ | あ | \xe38182 | \xe38182 | \xe38182
ア | ア | ア | \xe382a2 | \xe382a2 | \xe382a2
い | い | い | \xe38184 | \xe38184 | \xe38184
イ | イ | イ | \xe382a4 | \xe382a4 | \xe382a4
う | う | う | \xe38186 | \xe38186 | \xe38186
ウ | ウ | ウ | \xe382a6 | \xe382a6 | \xe382a6
(15 rows)
POC=# select a,b,c,a::bytea a_byte,b::bytea b_byte,c::bytea c_byte from T_COLLATE order by c;
a | b | c | a_byte | b_byte | c_byte
----+----+----+----------+----------+----------
1 | 1 | 1 | \x31 | \x31 | \x31
2 | 2 | 2 | \x32 | \x32 | \x32
3 | 3 | 3 | \x33 | \x33 | \x33
a | a | a | \x61 | \x61 | \x61
A | A | A | \x41 | \x41 | \x41
b | b | b | \x62 | \x62 | \x62
B | B | B | \x42 | \x42 | \x42
c | c | c | \x63 | \x63 | \x63
C | C | C | \x43 | \x43 | \x43
あ | あ | あ | \xe38182 | \xe38182 | \xe38182
ア | ア | ア | \xe382a2 | \xe382a2 | \xe382a2
い | い | い | \xe38184 | \xe38184 | \xe38184
イ | イ | イ | \xe382a4 | \xe382a4 | \xe382a4
う | う | う | \xe38186 | \xe38186 | \xe38186
ウ | ウ | ウ | \xe382a6 | \xe382a6 | \xe382a6
(15 rows)
Order by等を利用した場合にCOLLATIONにより意図しない結果になる事も留意
TIP①: 大文字、小文字を区別しないようには以下の文字列型を利用する事も可能です。
F.8. citext
citextモジュールは、大文字小文字の区別がない文字列型を提供します。 これは値の比較の際、基本的に内部でlowerを呼び出します。 この他はほぼtextと同様に動作します。
TIP②:LIKEで大文字小文字を区別しないようにする場合はILIKEを利用
POC=# select * from members;
id | name | age | salary | description | regist
----+------+-----+--------+-------------+------------
1 | Mr.T | 20 | 100 | | 2022-03-18
2 | Mr.U | 21 | 101 | | 2022-03-18
3 | Mr.V | 22 | 102 | | 2022-03-18
(3 rows)
POC=# select * from members where name like 'mr%';
id | name | age | salary | description | regist
----+------+-----+--------+-------------+--------
(0 rows)
POC=# select * from members where name ilike 'mr%';
id | name | age | salary | description | regist
----+------+-----+--------+-------------+------------
1 | Mr.T | 20 | 100 | | 2022-03-18
2 | Mr.U | 21 | 101 | | 2022-03-18
3 | Mr.V | 22 | 102 | | 2022-03-18
(3 rows)
POC=#