SQLを実行すると、データベースにてParserが構文チェックしてSQL文にエラーが無いか確認した後に、RewriterがSQLを内部的に書き換えます。書き換えられたSQLをOptimizerがどのように実行するかを統計情報を参照し決定します。その為、適切な統計情報は、最適なレスポンスでSQLを実行する為に必要となります。

統計情報:テーブル内のデータ量や粒度等の情報を含んでいて、サーバー側の設定(パラメータ)と掛け合わせて実行計画を作成し、Executerが処理を実行します。
In Case of MySQL
オプティマイザ統計は、innodb_stats_persistent=ON または個々のテーブルが STATS_PERSISTENT=1 で定義されている場合、ディスクに永続化されます。innodb_stats_persistent はデフォルトで有効になっています。以前は、サーバーの再起動時および他のタイプの操作後にオプティマイザ統計がクリアされ、次のテーブルアクセスで再計算されていました。 したがって、統計を再計算すると、クエリー実行計画の選択肢やクエリーパフォーマンスの変動につながる様々な見積りが生成される可能性があります。
デフォルトで有効になっている innodb_stats_auto_recalc 変数は、テーブルが 10% を超える行に変更された場合に統計を自動的に計算するかどうかを制御します。 テーブルの作成または変更時に STATS_AUTO_RECALC 句を指定して、個々のテーブルの自動統計再計算を構成することもできます。
innodb_stats_auto_recalc が無効になっている場合は、インデックス付けされたカラムを大幅に変更した後に ANALYZE TABLE ステートメントを実行することで、オプティマイザ統計の正確性を確保できます。 データのロード後に実行する設定スクリプトに ANALYZE TABLE を追加し、アクティビティが少ないときにスケジュールで ANALYZE TABLE を実行することも検討できます。
既存のテーブルにインデックスを追加する場合、またはカラムを追加または削除する場合、innodb_stats_auto_recalc の値に関係なく、インデックス統計が計算されて innodb_index_stats テーブルに追加されます。
15.8.10.1 永続的オプティマイザ統計のパラメータの構成

インスタン全体での設定
mysql> show global variables like 'innodb_stats_%';
+--------------------------------------+-------------+
| Variable_name | Value |
+--------------------------------------+-------------+
| innodb_stats_auto_recalc | ON |
| innodb_stats_include_delete_marked | OFF |
| innodb_stats_method | nulls_equal |
| innodb_stats_on_metadata | OFF |
| innodb_stats_persistent | ON |
| innodb_stats_persistent_sample_pages | 20 |
| innodb_stats_transient_sample_pages | 8 |
+--------------------------------------+-------------+
7 rows in set (0.00 sec)永続的統計テーブル
mysql> desc mysql.innodb_table_stats;
+--------------------------+
| Field |
+--------------------------+
| database_name |データベース名
| table_name |テーブル名
| last_update |行を更新した時間
| n_rows |テーブル内の行数
| clustered_index_size |PKのサイズ (ページ数)
| sum_of_other_index_sizes |PK以外のインデックス合計サイズ (ページ数)
+--------------------------+
mysql> desc mysql.innodb_index_stats;
+------------------+
| Field |
+------------------+
| database_name |データベース名
| table_name |テーブル名
| index_name |インデックス名
| last_update |行を更新した時間
| stat_name |stat_value カラムに値がレポートされている統計名
| stat_value |stat_name カラムで名前が指定されている統計の値
| sample_size |stat_value カラムに示されている推定値のサンプリングページ数
| stat_description |stat_name カラムで名前が指定されている統計の説明
+------------------+innodb_table_stats テーブルおよび innodb_index_stats テーブルは手動で更新可能です。
実際にする事は、殆ど無いと思いますが、特定のクエリー最適化計画を強制的に実行したり、代替計画をテストできます。統計を手動で更新する場合は、FLUSH TABLE tbl_name ステートメントを使用して更新された統計をロードします。

テーブル毎の設定
CREATE TABLE `t_stat_test` (
`id` int(8) NOT NULL auto_increment,
`data` varchar(255),
`date` datetime default now(),
PRIMARY KEY (`id`),
INDEX `DATE_IX` (`date`)
) ENGINE=InnoDB,
STATS_PERSISTENT=1,
STATS_AUTO_RECALC=1,
STATS_SAMPLE_PAGES=25;STATS_PERSISTENT
1の値を指定するとテーブルの永続統計が有効
0の値を指定するとテーブルの永続統計が無効
STATS_AUTO_RECALC
1の値を指定するとテーブルデータの10% が変更されたときに統計が再計算されます。
0の値を指定するとテーブルの自動再計算は行われません。
STATS_SAMPLE_PAGES
ANALYZE TABLE 操作などによって、インデックス付けされたカラムのカーディナリティおよびその他の統計が計算される場合にサンプリングするインデックスページの数を指定します。
1ページの内には複数のデータが存在します。
ヒストグラム (MySQL8.0.3以降)
ヒストグラム統計は、主にインデックス付けされていないカラムに役立ちます。 ヒストグラム統計が適用可能なカラムにインデックスを追加すると、オプティマイザが行の見積りを行うのにも役立ちます。 トレードオフは次のとおりです
① テーブルデータが変更された場合は、インデックスを更新する必要があります。
②ヒストグラムはオンデマンドでのみ作成または更新されるため、テーブルデータの変更時にオーバーヘッドは発生しません。 一方、統計は、次回更新されるまで、テーブルの変更が発生すると徐々に期限切れになります。
オプティマイザは、ヒストグラム統計から取得したものよりも範囲オプティマイザ行の見積りを優先します。 オプティマイザが範囲オプティマイザが適用されると判断した場合、ヒストグラム統計は使用されません。
8.9.6 オプティマイザ統計
Histogramが格納されるテーブル

ANALYZE + UPDATE HISTOGRAMでヒストグラムを作成
mysql> use POC
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> show global variables like 'histogram_generation_max_mem_size';
+-----------------------------------+----------+
| Variable_name | Value |
+-----------------------------------+----------+
| histogram_generation_max_mem_size | 20000000 |
+-----------------------------------+----------+
1 row in set (0.00 sec)
mysql> select * from INFORMATION_SCHEMA.COLUMN_STATISTICS;
Empty set (0.00 sec)
mysql> desc t_autoincrement;
+-------+--------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-------+--------------+------+-----+---------+----------------+
| id | bigint | NO | PRI | NULL | auto_increment |
| note | varchar(100) | NO | | - | |
+-------+--------------+------+-----+---------+----------------+
2 rows in set (0.02 sec)
mysql> ANALYZE TABLE t_autoincrement UPDATE HISTOGRAM ON note WITH 16 BUCKETS\G
*************************** 1. row ***************************
Table: POC.t_autoincrement
Op: histogram
Msg_type: status
Msg_text: Histogram statistics created for column 'note'.
1 row in set (0.65 sec)
mysql> select * from INFORMATION_SCHEMA.COLUMN_STATISTICS\G
*************************** 1. row ***************************
SCHEMA_NAME: POC
TABLE_NAME: t_autoincrement
COLUMN_NAME: note
HISTOGRAM: {"buckets": [["base64:type254:VGhpcyBpcyB0ZXN0IGxvb3AgZm9yIGxvZyBvbiBvZmY=", 1.0]], "data-type": "string", "null-values": 0.0, "collation-id": 255, "last-updated": "2022-03-28 00:55:18.645452", "sampling-rate": 1.0, "histogram-type": "singleton", "number-of-buckets-specified": 16}
1 row in set (0.13 sec)
mysql> SELECT TABLE_NAME, COLUMN_NAME,
-> HISTOGRAM->>'$."data-type"' AS 'data-type',
-> JSON_LENGTH(HISTOGRAM->>'$."buckets"') AS 'bucket-count'
-> FROM INFORMATION_SCHEMA.COLUMN_STATISTICS;
+-----------------+-------------+-----------+--------------+
| TABLE_NAME | COLUMN_NAME | data-type | bucket-count |
+-----------------+-------------+-----------+--------------+
| t_autoincrement | note | string | 1 |
+-----------------+-------------+-----------+--------------+
1 row in set (0.00 sec)
mysql> SELECT HISTOGRAM->>'$."sampling-rate"' FROM INFORMATION_SCHEMA.COLUMN_STATISTICS;
+---------------------------------+
| HISTOGRAM->>'$."sampling-rate"' |
+---------------------------------+
| 1.0 |
+---------------------------------+
1 row in set (0.00 sec)
ANALYZE TABLE で DROP HISTOGRAM 句を使用すると、指定したテーブルのカラムのヒストグラム統計がデータディクショナリから削除されます。

INDEXが付与された状態での確認
HISTOGRAMを作成しても、Indexの方がレスポンスが良いのでIndexが利用されている。
mysql> select * from t_stat_test limit 10;
+----+--------------------------------------------+---------------------+
| id | data | date |
+----+--------------------------------------------+---------------------+
| 1 | 統計情報をテーブル単位で設定 | 2022-03-30 10:08:47 |
| 2 | 統計情報をテーブル単位で設定 | 2022-03-31 06:44:26 |
| 3 | 統計情報をテーブル単位で設定 | 2022-03-31 06:44:28 |
| 4 | 統計情報をテーブル単位で設定 | 2022-03-31 06:44:29 |
| 5 | 統計情報をテーブル単位で設定 | 2022-03-31 06:44:29 |
| 6 | 統計情報をテーブル単位で設定 | 2022-03-31 06:44:30 |
| 7 | 統計情報をテーブル単位で設定 | 2022-03-31 06:44:31 |
| 8 | 統計情報をテーブル単位で設定 | 2022-03-31 06:44:31 |
| 9 | 統計情報をテーブル単位で設定 | 2022-03-31 06:44:32 |
| 10 | 統計情報をテーブル単位で設定 | 2022-03-31 06:44:33 |
+----+--------------------------------------------+---------------------+
10 rows in set (0.00 sec)
mysql> show create table t_stat_test\G
*************************** 1. row ***************************
Table: t_stat_test
Create Table: CREATE TABLE `t_stat_test` (
`id` int NOT NULL AUTO_INCREMENT,
`data` varchar(255) COLLATE utf8mb4_general_ci DEFAULT NULL,
`date` datetime DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (`id`),
KEY `DATE_IX` (`date`)
) ENGINE=InnoDB AUTO_INCREMENT=12 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci STATS_PERSISTENT=1 STATS_AUTO_RECALC=1 STATS_SAMPLE_PAGES=25
1 row in set (0.01 sec)
mysql> ANALYZE TABLE t_stat_test UPDATE HISTOGRAM ON date WITH 16 BUCKETS\G
*************************** 1. row ***************************
Table: POC.t_stat_test
Op: histogram
Msg_type: status
Msg_text: Histogram statistics created for column 'date'.
1 row in set (0.03 sec)
mysql> SELECT HISTOGRAM->>'$."sampling-rate"'
-> FROM INFORMATION_SCHEMA.COLUMN_STATISTICS
-> WHERE TABLE_NAME = "t_stat_test" AND COLUMN_NAME = "date";
+---------------------------------+
| HISTOGRAM->>'$."sampling-rate"' |
+---------------------------------+
| 1.0 |
+---------------------------------+
1 row in set (0.00 sec)
mysql> explain format=JSON select * from t_stat_test where date >= '2022-03-31 06:44:30'\G
*************************** 1. row ***************************
EXPLAIN: {
"query_block": {
"select_id": 1,
"cost_info": {
"query_cost": "2.96"
},
"table": {
"table_name": "t_stat_test",
"access_type": "range",
"possible_keys": [
"DATE_IX"
],
"key": "DATE_IX",
"used_key_parts": [
"date"
],
"key_length": "6",
"rows_examined_per_scan": 6,
"rows_produced_per_join": 6,
"filtered": "100.00",
"index_condition": "(`POC`.`t_stat_test`.`date` >= TIMESTAMP'2022-03-31 06:44:30')",
"cost_info": {
"read_cost": "2.36",
"eval_cost": "0.60",
"prefix_cost": "2.96",
"data_read_per_join": "6K"
},
"used_columns": [
"id",
"data",
"date"
]
}
}
}
1 row in set, 1 warning (0.01 sec)
IndexをDROPして、Histgramが使われるか確認
“histogram_selectivity”: 0.545455となっている事が確認出来る。
mysql> alter table t_stat_test drop index `DATE_IX`;
Query OK, 0 rows affected (0.08 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> explain format=JSON select * from t_stat_test where date >= '2022-03-31 06:44:30'\G
*************************** 1. row ***************************
EXPLAIN: {
"query_block": {
"select_id": 1,
"cost_info": {
"query_cost": "1.35"
},
"table": {
"table_name": "t_stat_test",
"access_type": "ALL",
"rows_examined_per_scan": 11,
"rows_produced_per_join": 6,
"filtered": "54.55",
"cost_info": {
"read_cost": "0.75",
"eval_cost": "0.60",
"prefix_cost": "1.35",
"data_read_per_join": "6K"
},
"used_columns": [
"id",
"data",
"date"
],
"attached_condition": "(`POC`.`t_stat_test`.`date` >= TIMESTAMP'2022-03-31 06:44:30')"
}
}
}
1 row in set, 1 warning (0.01 sec)
mysql> SELECT * FROM INFORMATION_SCHEMA.OPTIMIZER_TRACE\G
*************************** 1. row ***************************
QUERY: explain format=JSON select * from t_stat_test where date >= '2022-03-31 06:44:30'
TRACE: {
"steps": [
{
"join_preparation": {
"select#": 1,
"steps": [
{
"expanded_query": "/* select#1 */ select `t_stat_test`.`id` AS `id`,`t_stat_test`.`data` AS `data`,`t_stat_test`.`date` AS `date` from `t_stat_test` where (`t_stat_test`.`date` >= '2022-03-31 06:44:30')"
}
]
}
},
{
"join_optimization": {
"select#": 1,
"steps": [
{
"condition_processing": {
"condition": "WHERE",
"original_condition": "(`t_stat_test`.`date` >= '2022-03-31 06:44:30')",
"steps": [
{
"transformation": "equality_propagation",
"resulting_condition": "(`t_stat_test`.`date` >= '2022-03-31 06:44:30')"
},
{
"transformation": "constant_propagation",
"resulting_condition": "(`t_stat_test`.`date` >= '2022-03-31 06:44:30')"
},
{
"transformation": "trivial_condition_removal",
"resulting_condition": "(`t_stat_test`.`date` >= TIMESTAMP'2022-03-31 06:44:30')"
}
]
}
},
{
"substitute_generated_columns": {
}
},
{
"table_dependencies": [
{
"table": "`t_stat_test`",
"row_may_be_null": false,
"map_bit": 0,
"depends_on_map_bits": [
]
}
]
},
{
"ref_optimizer_key_uses": [
]
},
{
"rows_estimation": [
{
"table": "`t_stat_test`",
"table_scan": {
"rows": 11,
"cost": 0.25
}
}
]
},
{
"considered_execution_plans": [
{
"plan_prefix": [
],
"table": "`t_stat_test`",
"best_access_path": {
"considered_access_paths": [
{
"rows_to_scan": 11,
"filtering_effect": [
{
"condition": "(`t_stat_test`.`date` >= TIMESTAMP'2022-03-31 06:44:30')",
"histogram_selectivity": 0.545455
}
],
"final_filtering_effect": 0.545455,
"access_type": "scan",
"resulting_rows": 6,
"cost": 1.35,
"chosen": true
}
]
},
"condition_filtering_pct": 100,
"rows_for_plan": 6,
"cost_for_plan": 1.35,
"chosen": true
}
]
},
{
"attaching_conditions_to_tables": {
"original_condition": "(`t_stat_test`.`date` >= TIMESTAMP'2022-03-31 06:44:30')",
"attached_conditions_computation": [
],
"attached_conditions_summary": [
{
"table": "`t_stat_test`",
"attached": "(`t_stat_test`.`date` >= TIMESTAMP'2022-03-31 06:44:30')"
}
]
}
},
{
"finalizing_table_conditions": [
{
"table": "`t_stat_test`",
"original_table_condition": "(`t_stat_test`.`date` >= TIMESTAMP'2022-03-31 06:44:30')",
"final_table_condition ": "(`t_stat_test`.`date` >= TIMESTAMP'2022-03-31 06:44:30')"
}
]
},
{
"refine_plan": [
{
"table": "`t_stat_test`"
}
]
}
]
}
},
{
"join_explain": {
"select#": 1,
"steps": [
]
}
}
]
}
MISSING_BYTES_BEYOND_MAX_MEM_SIZE: 0
INSUFFICIENT_PRIVILEGES: 0
1 row in set (0.01 sec)
mysql>

備考
MySQLの統計情報は実行プランを作成する為に利用されますが、ヒント句を利用して特定の処理を意図的にコントロールしたり、以下の様な重みづけをインスタンス単位で変更してオプシティマイザーをコントロールする事が出来ます。但し、インスタンス全体でコントロールするケースは殆ど無いでしょう。遅い処理にヒント句を利用して、該当の処理を改善する事が妥当かと思います。

In Case of PostgreSQL
MySQL同様にデータベース内のテーブルやインデックスの行数やサイズ、各列のデータの重複度合いや出現頻度、分布状況などから生成された統計情報を利用して、最適な実行プランを決定しSQLを実行します。
統計情報はMySQL同様にANALYZEコマンドが収集します。また、VACUUM時に実行さる、VACUUM ANALYZEコマンドでも収集され更新されます。
サンプリングされるデータ数に関して
ALTER TABLE SET STATISTICSで列特定の目的セットの無いテーブル列に対し、デフォルトの統計対象を設定します。 より大きい値はANALYZEに必要な時間を増加させますが、プランナの予測の品質を向上させます。 デフォルトは100です。
19.7.4. その他のプランナオプション
留意:MySQLでも同様ですが、サンプリング数を上げるとANALYZE処理の負荷も増えます。(VACCUM含む)

統計情報の確認
pg_statsビューはpg_statisticカタログの情報にアクセスするためのビューです。このViewを参照してどのようなデータ分布なのかを確認する事が出来ます。

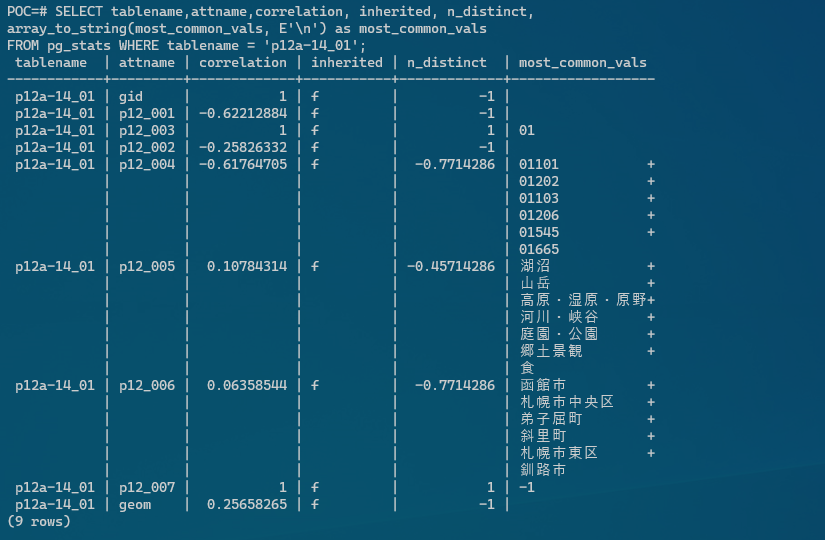
SELECT tablename,attname,correlation, inherited, n_distinct,
array_to_string(most_common_vals, E'\n') as most_common_vals
FROM pg_stats WHERE tablename = '<テーブル名>';
備考:n_distinctが0より大きい値は列内の個別値の推定数。ゼロより小さければ行数で個別値を割算した数字の負数です。例えば-1は個別値の数が行数と等しいような一意な列を表します。一意の値であれば、より効率良くインデックスを利用する事が出来るでしょう。
テーブルの行数に関する統計情報はpg_classを参照

Analyzeによる統計情報の更新
POC=# select count(*) from t1;
count
---------
3000000
(1 row)
POC=# \x
Expanded display is on.
POC=# SELECT * FROM pg_stat_all_tables where relname = 't1';
-[ RECORD 1 ]-------+--------
relid | 17435
schemaname | public
relname | t1
seq_scan | 4
seq_tup_read | 6000000
idx_scan | 0
idx_tup_fetch | 0
n_tup_ins | 0
n_tup_upd | 0
n_tup_del | 0
n_tup_hot_upd | 0
n_live_tup | 0
n_dead_tup | 0
n_mod_since_analyze | 0
n_ins_since_vacuum | 0
last_vacuum |
last_autovacuum |
last_analyze |
last_autoanalyze |
vacuum_count | 0
autovacuum_count | 0
analyze_count | 0
autoanalyze_count | 0
POC=# select * from pg_class where relname = 't1';
-[ RECORD 1 ]-------+------
oid | 17435
relname | t1
relnamespace | 2200
reltype | 17437
reloftype | 0
relowner | 10
relam | 2
relfilenode | 17505
reltablespace | 0
relpages | 22059
reltuples | 3e+06
relallvisible | 0
reltoastrelid | 0
relhasindex | t
relisshared | f
relpersistence | p
relkind | r
relnatts | 3
relchecks | 0
relhasrules | f
relhastriggers | f
relhassubclass | f
relrowsecurity | f
relforcerowsecurity | f
relispopulated | t
relreplident | d
relispartition | f
relrewrite | 0
relfrozenxid | 557
relminmxid | 1
relacl |
reloptions |
relpartbound |
POC=# analyze t1;
ANALYZE
POC=# SELECT * FROM pg_stat_all_tables where relname = 't1';
-[ RECORD 1 ]-------+------------------------------
relid | 17435
schemaname | public
relname | t1
seq_scan | 4
seq_tup_read | 6000000
idx_scan | 0
idx_tup_fetch | 0
n_tup_ins | 0
n_tup_upd | 0
n_tup_del | 0
n_tup_hot_upd | 0
n_live_tup | 3000000
n_dead_tup | 0
n_mod_since_analyze | 0
n_ins_since_vacuum | 0
last_vacuum |
last_autovacuum |
last_analyze | 2022-04-02 11:08:10.238687+09
last_autoanalyze |
vacuum_count | 0
autovacuum_count | 0
analyze_count | 1
autoanalyze_count | 0
POC=# select * from pg_class where relname = 't1';
-[ RECORD 1 ]-------+------
oid | 17435
relname | t1
relnamespace | 2200
reltype | 17437
reloftype | 0
relowner | 10
relam | 2
relfilenode | 17505
reltablespace | 0
relpages | 22059
reltuples | 3e+06
relallvisible | 0
reltoastrelid | 0
relhasindex | t
relisshared | f
relpersistence | p
relkind | r
relnatts | 3
relchecks | 0
relhasrules | f
relhastriggers | f
relhassubclass | f
relrowsecurity | f
relforcerowsecurity | f
relispopulated | t
relreplident | d
relispartition | f
relrewrite | 0
relfrozenxid | 557
relminmxid | 1
relacl |
reloptions |
relpartbound |
POC=#
Auto Analyzeの実行タイミング
” select 50 + テーブルデータの件数 * 0.1″ のデータが更新されるとAnalyzeが自動的に実行されます。
POC=# select name,setting,category from pg_settings where name like '%analyze%';
name | setting | category
---------------------------------+---------+------------
autovacuum_analyze_scale_factor | 0.1 | Autovacuum
autovacuum_analyze_threshold | 50 | Autovacuum
(2 rows)
POC=# select count(*) from t1;
count
---------
3000000
(1 row)
POC=# select 50 + 3000000 * 0.1;
?column?
----------
300050.0
(1 row)
POC=# select relname,last_analyze,last_autoanalyze,now() from pg_stat_all_tables where relname = 't1';
relname | last_analyze | last_autoanalyze | now
---------+-------------------------------+-------------------------------+-------------------------------
t1 | 2022-04-02 11:08:10.238687+09 | 2022-04-03 04:14:33.944844+09 | 2022-04-03 04:17:37.916641+09
(1 row)
POC=# update t1 set note = 'check if last_autoanalyze will be updated' where id < 310000;
UPDATE 309999
POC=# select relname,last_analyze,last_autoanalyze,now() from pg_stat_all_tables where relname = 't1';
relname | last_analyze | last_autoanalyze | now
---------+-------------------------------+-------------------------------+-------------------------------
t1 | 2022-04-02 11:08:10.238687+09 | 2022-04-03 04:18:30.724596+09 | 2022-04-03 04:18:32.757311+09
(1 row)
POC=#統計情報の精度を確認
以下の様にEXPLAIN ANALYZEを実行する事で、推定コストで見積もられた行数:772577 とActualにて実際に処理された行数:899994の差異を比較する事で統計情報と実際のデータ数の差異を確認する事が出来ます。
POC=# explain analyze select * from trains where id >= 1000 and id < 2000000;
QUERY PLAN
-----------------------------------------------------------------------------------------------------------------
Seq Scan on trains (cost=0.00..21207.87 rows=772577 width=35) (actual time=0.014..176.064 rows=899994 loops=1)
Filter: ((id >= 1000) AND (id < 2000000))
Rows Removed by Filter: 100010
Planning Time: 0.126 ms
Execution Time: 218.888 ms
(5 rows)
POC=# analyze trains;
ANALYZE
POC=# explain analyze select * from trains where id >= 1000 and id < 2000000;
QUERY PLAN
-----------------------------------------------------------------------------------------------------------------
Seq Scan on trains (cost=0.00..23334.06 rows=899422 width=35) (actual time=0.012..172.563 rows=899994 loops=1)
Filter: ((id >= 1000) AND (id < 2000000))
Rows Removed by Filter: 100010
Planning Time: 0.316 ms
Execution Time: 214.738 ms
(5 rows)
POC=#
推定コストの算出
POC=# select name,setting,category from pg_settings where name like '%cost';
name | setting | category
-------------------------+---------+---------------------------------------
cpu_index_tuple_cost | 0.005 | Query Tuning / Planner Cost Constants
cpu_operator_cost | 0.0025 | Query Tuning / Planner Cost Constants
cpu_tuple_cost | 0.01 | Query Tuning / Planner Cost Constants
jit_above_cost | 100000 | Query Tuning / Planner Cost Constants
jit_inline_above_cost | 500000 | Query Tuning / Planner Cost Constants
jit_optimize_above_cost | 500000 | Query Tuning / Planner Cost Constants
parallel_setup_cost | 1000 | Query Tuning / Planner Cost Constants
parallel_tuple_cost | 0.1 | Query Tuning / Planner Cost Constants
random_page_cost | 4 | Query Tuning / Planner Cost Constants
seq_page_cost | 1 | Query Tuning / Planner Cost Constants
(10 rows)
POC=#
例) Sequential Costの算出
推定コストは(ディスクページ読み取り * seq_page_cost)+(スキャンした行 * cpu_tuple_cost)と計算されます。デフォルトでは、seq_page_costは1.0、cpu_tuple_costは0.01となります。
参照:14.1. EXPLAINの利用14.1. EXPLAINの利用
POC=# explain select * from t1;
QUERY PLAN
-------------------------------------------------------------
Seq Scan on t1 (cost=0.00..52059.00 rows=3000000 width=31)
(1 row)
POC=# select relpages from pg_class where relname = 't1';
relpages
----------
22059
(1 row)
POC=# select (22059 * 1.0) + (3000000 * 0.01);
?column?
----------
52059.00
(1 row)
統計情報を固定化して、実行計画を制御する
pg_dbms_stats
pg_dbms_statsを利用して統計情報を固定化し、常にその統計情報が利用されるようにチューニングする方法があります。
参照:pg_dbms_statsで統計情報を固定化して、実行計画を制御する
その他:以前に基本的な説明を以下のスライドにまとめたので参考までに。